


XGBoost 2.0 is Here to Improve Your Time Series Forecasts
A Practical Guide to XGBoost 2.0 and How to Forecast Time Series


In the ever-evolving landscape of machine learning, XGBoost has established itself as a powerhouse algorithm for a wide range of predictive tasks. Now, with the release of XGBoost 2.0, a new era in time series prediction is upon us. This latest version brings forth a myriad of enhancements specifically tailored to tackle the complexities of time-dependent data.
Introduction to XGBoost and What’s New in XGBoost 2.0
Imagine you’re trying to solve a complex puzzle. Each piece of the puzzle represents a small part of the solution. XGBoost is like having a group of experts, each specializing in a particular type of puzzle piece. They work together to solve the puzzle. The algorithm is all about improving, or boosting, the performance of a model. It starts with a simple model, like a decision tree, and gradually makes it better.
XGBoost pays extreme attention to its mistakes. It looks at the pieces of the puzzle it got wrong and focuses on solving those first. Instead of relying on a single expert to solve the entire puzzle, it uses many experts (decision trees). Each expert gives their opinion on how to solve the puzzle, and they vote together to make the final decision.
XGBoost then goes through a lot of practice puzzles (training data) to train its experts. It learns from its mistakes and gets better over time. It also constantly checks how well it’s doing and makes adjustments. It’s like each expert is given a chance to reevaluate their opinion and improve their piece of the puzzle.
The final solution is the combination of all the expert opinions. This combination often leads to a much better result than just one expert could achieve.
In version 2.0, the development team has been focusing on enhancing XGBoost with vector-leaf tree models for multi-target regression and classification tasks. This new feature allows XGBoost to construct a single tree for all targets, rather than building separate models for each target as it did previously.
This approach brings several advantages and trade-offs compared to the traditional method. It can mitigate overfitting, generate more compact models, and create trees that account for correlations between targets. Additionally, users can incorporate both vector-leaf and scalar-leaf trees in their training sessions using a callback mechanism. Here are some improvements in the second version:
Moving forward, users only require the device parameter to specify the device for execution, along with its ordinal position.
In upcoming versions, the default tree method will be hist. Previously, XGBoost automatically selected either approx or exact based on the input data and training environment. This change in default setting aims to enhance the efficiency and consistency of model training in XGBoost.
Preliminary support for employing the approx tree method on GPU. While the performance of this method is not yet fully optimized, it is feature-complete, with the exception of the JVM packages.
XGBoost introduces a new parameter called max_cached_hist_node, allowing users to set a limit on the CPU cache size allocated for histograms. This feature aims to prevent XGBoost from overly aggressive caching of histograms. If the cache is disabled, it may lead to a decrease in performance.
The most recent version of XGBoost has acquired a collection of new features tailored for ranking tasks.
In earlier versions, the base_score was a fixed value that could be designated as a training parameter. In the updated version, XGBoost can autonomously determine this parameter by analyzing the input labels to enhance accuracy.
The XGBoost algorithm has been enhanced to accommodate quantile regression, which entails minimizing the quantile loss function. Additionally, XGBoost enables training with multiple target quantiles concurrently, utilizing one tree for each quantile.
✨ Important note
If you already have xgboost 1.7 installed, you can simply uninstall it using pip uninstall xgboost and then reinstalling the newest version using pip install xgboost.
If you want to see more of my work, you can visit my website for the books catalogue by simply following this link:
Forecasting Time Series in Python
Similar to the older version, we can use XGBoost to forecast time series efficiently. Here are the steps we will follow for this experiment:
Download and import the COT JPY data from here.
Take the difference of the data in order to make it stationary.
Split the data into training and test sets (while using lagged values as features or predictors). Fit and predict using XGBoost algorithm.
Evaluate the model.
✨ Important note
The COT report, or commitments of traders report, is a weekly publication by the U.S. CFTC that provides information on the positions of various market participants, including commercial hedgers, large speculators, and small traders, in the futures and options markets. It offers valuable insights into the sentiment and positioning of these groups, helping traders and investors gauge potential market trends and reversals. The report is commonly used for analyzing commodity and financial futures markets to make informed trading decisions.
Use the following code to perform the study:
from xgboost import XGBRegressor
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
data = np.reshape(pd.read_excel('COT_JPY.xlsx').values, (-1))
data = np.diff(data)
def data_preprocessing(data, num_lags, train_test_split):
# Prepare the data for training
x = []
y = []
for i in range(len(data) - num_lags):
x.append(data[i:i + num_lags])
y.append(data[i+ num_lags])
# Convert the data to numpy arrays
x = np.array(x)
y = np.array(y)
# Split the data into training and testing sets
split_index = int(train_test_split * len(x))
x_train = x[:split_index]
y_train = y[:split_index]
x_test = x[split_index:]
y_test = y[split_index:]
return x_train, y_train, x_test, y_test
x_train, y_train, x_test, y_test = data_preprocessing(data, 80, 0.80)
# Create the model
model = XGBRegressor(random_state = 0, n_estimators = 64, max_depth = 64)
# Fit the model to the data
model.fit(x_train, y_train)
y_pred_xgb = model.predict(x_test)
# Plotting
plt.plot(y_pred_xgb[-100:], label='Predicted Data | XGBoost', linestyle='--', marker = '.', color = 'orange')
plt.plot(y_test[-100:], label='True Data', marker = '.', alpha = 0.7, color = 'blue')
plt.legend()
plt.grid()
plt.axhline(y = 0, color = 'black', linestyle = '--')
same_sign_count = np.sum(np.sign(y_pred_xgb) == np.sign(y_test)) / len(y_test) * 100
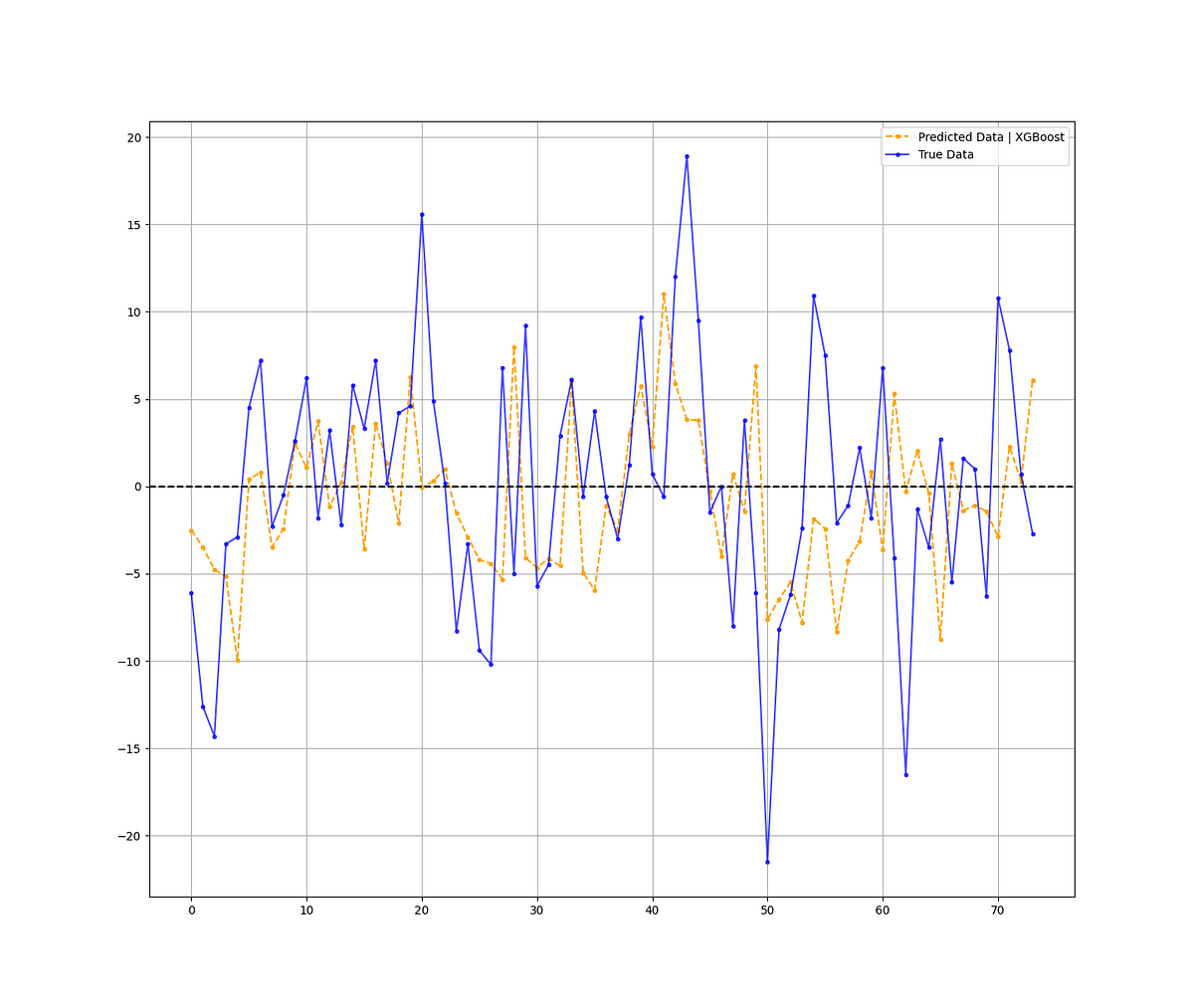
print('Hit Ratio XGBoost = ', same_sign_count, '%')The following chart shows the predictions (orange) and the real data (blue):
✨ Important note
Why make the data stationary? Making the data stationary before forecasting is important because many time series forecasting techniques assume that the underlying data generating process is stationary. Stationarity refers to the statistical properties of a time series remaining constant over time.
The results of the model are as follows:
Hit Ratio XGBoost = 60.81 %The model seems to be able to predict correctly the direction of the change in the COT JPY time series around 61% of the time. This can be improved but it is a good start.
You can also check out my other newsletter The Weekly Market Sentiment Report that sends weekly directional views every weekend to highlight the important trading opportunities using a mix between sentiment analysis (COT report, put-call ratio, etc.) and rules-based technical analysis.
If you liked this article, do not hesitate to like and comment, to further the discussion!