
Time Series Forecasting With Bayesian Regression
From Theory to Application: Bayesian Ridge Regression in Action


Bayesian ridge regression stands as a powerful and versatile technique. It is a Bayesian approach to linear regression that offers a unique perspective on modeling and prediction. This approach combines the best of both worlds: the regularization properties of ridge regression and the probabilistic framework of Bayesian inference.
Bayesian Ridge Regression
Before delving into Bayesian ridge regression, let’s first understand the foundation upon which it builds. Ridge regression is a linear regression technique designed to tackle the issue of multicollinearity in predictive modeling. When predictors (features) in a dataset are highly correlated, traditional linear regression models can become unstable and yield unreliable coefficient estimates.
Ridge regression addresses this by introducing a regularization term to the linear regression objective function. This regularization term, often referred to as the L2 penalty, encourages the model to distribute the weights (coefficients) of the predictors more evenly, effectively reducing the impact of multicollinearity.
What sets Bayesian ridge regression apart is its incorporation of Bayesian statistics. Bayesian methods treat model parameters as random variables, allowing for the modeling of uncertainty. In the context of linear regression, this means that instead of producing point estimates for coefficients, Bayesian ridge regression provides probability distributions over the possible values of these coefficients.
The key advantage of machine learning for time series predictions lies in its adaptability and scalability. These models can learn from large datasets, automatically detect patterns and trends, and adapt to changing conditions, making them invaluable for real-world applications. As businesses and researchers increasingly seek accurate forecasts and insights from their time series data, machine learning continues to play a central role in shaping the future of time series analysis and prediction.
Implementation in Python
Let’s implement this regression by using an example on the S&P 500 index. The aim is to predict the next change in value of the index. By trying to predict the change, you are ensuring data stationarity. Be careful, do not try to predict prices using machine learning models as they require stationarity.
The plan of attack is as follows:
Import the S&P 500 data using Python.
Split the data between training and test sets.
Choose a number of lagged values that the model uses to fit and understand the data.
Predict on never-seen-before data (this is called the test set).
Evaluate the performance using the root mean squared error (RMSE).
Plot the predicted versus the real data.
This is of course an introductory task, as more complex analyses require more complex steps. But, let’s start step by step.
Use the following code to import the data and plot it:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import BayesianRidge
from sklearn.metrics import mean_squared_error, mean_absolute_error
import math
import pandas_datareader as pdr
start_date = '1960-01-01'
end_date = '2020-01-01'
# Set the time index if it's not already set
data = (pdr.get_data_fred('SP500', start = start_date, end = end_date).dropna())
# Plot the time series to visualize it
plt.figure(figsize=(12, 6))
plt.plot(data)
plt.title('S&P 500 Index')
plt.xlabel('Date')
plt.ylabel('Value')
plt.grid()
plt.show()
Difference (transform) the data and split it to four different time series:
training data (inputs): Often referred to as x_train, this is the data that will train your model and make it ready for the future. Examples can include past values of technical indicators, exogenous variables, or past differenced prices.
training data (outputs): Often referred to as y_train, this is that data that explains the inputs from the training set. They are the right answers, where the model tries to calibrate its predictions on.
test data (inputs): Often referred to as x_test, this is the data that will be used as a basis of prediction in the never-seen-before data.
test data (outputs): Often referred to as y_test, this is the data that will be used as a comparison for the quality of the predicted data (that is often referred to as y_predicted)
Here’s an example of a split between the training data and the test data.
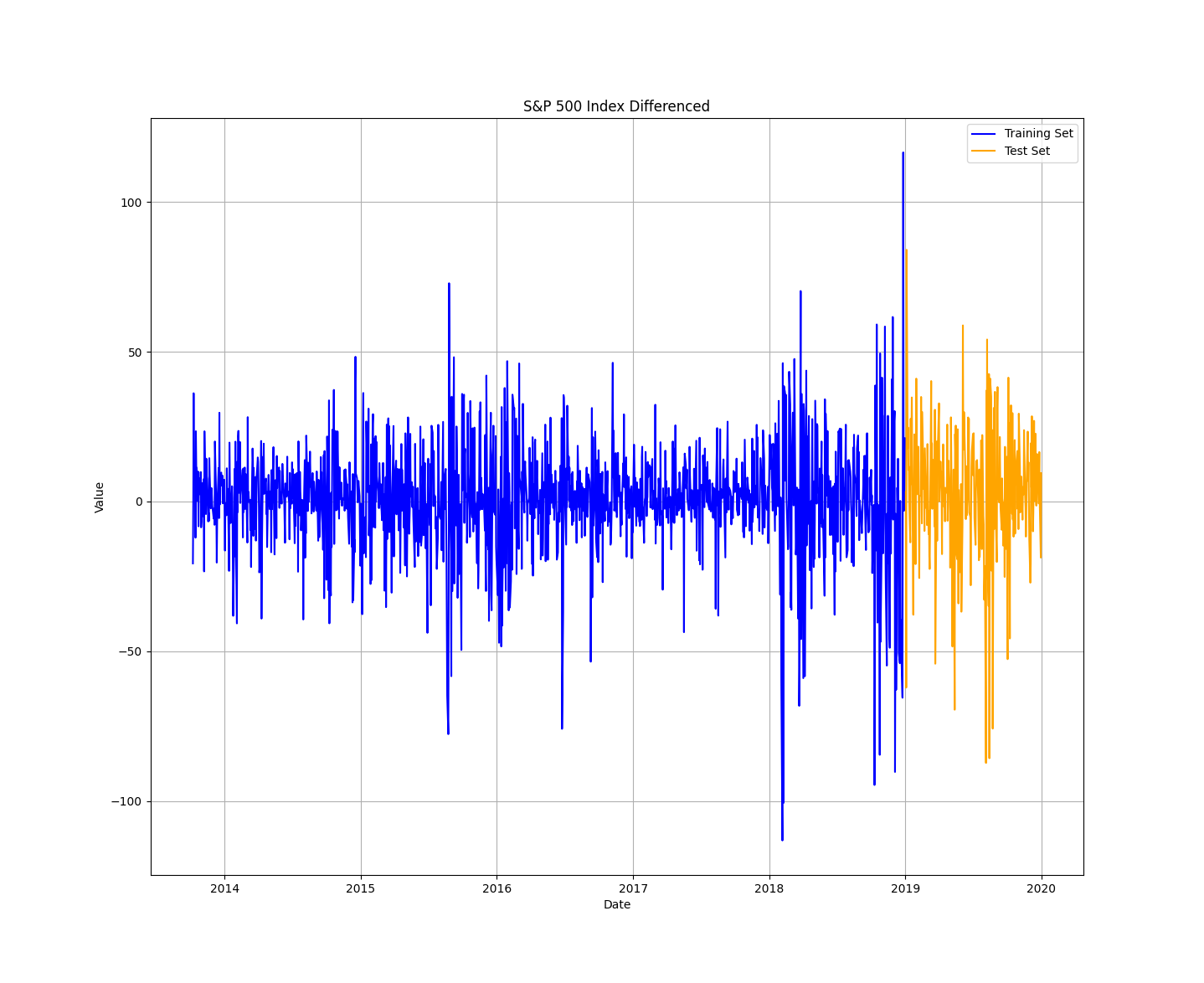
The following code implements the split, trains the model, predicts the data, and outputs the RMSE. As a reminder, RMSE stands for “Root Mean Square Error.” It is a commonly used metric for measuring the accuracy of a predictive model, particularly in the context of regression analysis and time series forecasting. RMSE quantifies the average magnitude of errors or residuals between the predicted values and the actual observed values in a dataset.
def data_preprocessing(data, num_lags, train_test_split):
# Prepare the data for training
x = []
y = []
for i in range(len(data) - num_lags):
x.append(data[i:i + num_lags])
y.append(data[i+ num_lags])
# Convert the data to numpy arrays
x = np.array(x)
y = np.array(y)
# Split the data into training and testing sets
split_index = int(train_test_split * len(x))
x_train = x[:split_index]
y_train = y[:split_index]
x_test = x[split_index:]
y_test = y[split_index:]
return x_train, y_train, x_test, y_test
start_date = '1960-01-01'
end_date = '2020-01-01'
# Set the time index if it's not already set
data = (pdr.get_data_fred('SP500', start = start_date, end = end_date).dropna())
# Perform differencing to make the data stationary
data_diff = data.diff().dropna()
# You can choose an appropriate split point based on your data
data_diff = np.reshape(np.array(data_diff), (-1))
x_train, y_train, x_test, y_test = data_preprocessing(data_diff, 100, 0.80)
# Create and train the Bayesian Ridge model
model = BayesianRidge()
model.fit(x_train, y_train)
# Predicting in-sample
y_predicted_train = np.reshape(model.predict(x_train), (-1, 1))
# Predicting out-of-sample
y_predicted = np.reshape(model.predict(x_test), (-1, 1))
# Step 6: Evaluate the model's performance
# Calculate evaluation metrics (e.g., RMSE, MAE, etc.)
rmse_train = math.sqrt(mean_squared_error(y_predicted_train, y_train))
rmse_test = math.sqrt(mean_squared_error(y_predicted, y_test))
print(f"RMSE of Training: {rmse_train}")
print(f"RMSE of Test: {rmse_test}")The output is as follows:
RMSE of Training: 17.477823110808675
RMSE of Test: 25.675763541622867Obviously, with such a simple model, the RMSE of the training will be much bigger than the one of the test. This is often the case anyway.
# Plot the actual vs. predicted values
plt.figure(figsize=(12, 6))
plt.plot(y_test[-50:], label = 'Actual', color = 'blue')
plt.plot(y_predicted[-50:], label = 'Predicted', color = 'red')
plt.legend()
plt.title('Bayesian Ridge Model - Actual vs. Predicted')
plt.ylabel('Value')
plt.show()
plt.grid()
plt.axhline(y = 0, color = 'black')The following chart shows the difference between the predicted values and the actual values.

For each blue dot, a prediction in parallel has been made. Positive predictions are above the zero line while negative predictions are below the zero line.
You can also check out my other newsletter The Weekly Market Sentiment Report that sends weekly directional views every weekend to highlight the important trading opportunities using a mix between sentiment analysis (COT report, put-call ratio, etc.) and rules-based technical analysis.
If you liked this article, do not hesitate to like and comment, to further the discussion!