


The Time Whisperer - Predicting the Future With LARS Algorithm
Using LARS to Predict Time Series


Machine learning englobes a wide array of different algorithms that are able to perform tasks such as regression and classification. It is always interesting to have at least a basic idea of these algorithms. This article presents the LARS algorithm and shows how to code it in hopes of predicting inflation numbers.
What is Least Angle Regression (LARS)?
Least Angle Regression (LARS) is a technique used in statistics and machine learning for fitting linear regression models. It’s particularly useful when dealing with datasets where the number of predictors (features) is large compared to the number of observations. In simple terms, it helps us find which predictors are most important in explaining the variation in the outcome variable.
✨ Important note
In other words, if you are using lagged values to estimate future values, make sure you use a bunch of lagged values (for example, using the latest 500 returns of the S&P 500 to predict the next return).
Imagine you have a bunch of predictors (like age, income, and education level), and you want to predict something (like house price). LARS helps you figure out which predictors are important and how they contribute to predicting the outcome.
Instead of blindly throwing all predictors into the mix, LARS starts with the predictor that has the highest correlation with the outcome variable. It then moves in the direction that explains the most variance in the outcome while keeping the relationships between predictors in mind.
✨ Important note
Correlation is a statistical measure that describes the strength and direction of a relationship between two variables. In simpler terms, it tells us how closely related two sets of data are. There are two main types of correlation:
* Positive correlation: When the values of one variable increase, the values of the other variable also tend to increase. Conversely, when one decreases, the other tends to decrease as well.
* Negative correlation: When the values of one variable increase, the values of the other variable tend to decrease, and vice versa.
As it progresses, LARS keeps adding predictors to the model in a stepwise manner. However, unlike traditional stepwise regression methods, LARS doesn’t just add or remove predictors at each step. Instead, it adds them gradually, in a way that allows it to “follow the path” of the most relevant predictors.
Think of it like climbing a mountain: LARS takes steps in the direction that gets it closer to the top (the best prediction), but it doesn’t rush straight there. It zigzags strategically, always aiming for the steepest slope (the most important predictors) while also avoiding going too far off course (overfitting). This method is especially useful in situations where you have more predictors than observations because it helps avoid overfitting and identifies the most influential predictors without needing to test every possible combination. Let’s compare with a more traditional machine learning algorithm; linear regression.
The main difference between LARS and traditional linear regression lies in how they approach the task of fitting a regression model.
Linear Regression is used to model the relationship between a dependent variable (the outcome you want to predict) and one or more independent variables (predictors or features). It finds the coefficients (weights) for each predictor that minimizes the sum of the squared differences between the predicted and actual values of the dependent variable.
LARS is a more sophisticated technique, particularly suitable for situations where you have a large number of predictors compared to the number of observations. Instead of considering all predictors at once, LARS starts with the predictor most correlated with the outcome variable. It then gradually adds more predictors, each time moving in the direction that best explains the variance in the outcome while keeping the relationships between predictors in mind.
This incremental approach allows LARS to efficiently identify the most influential predictors and their contribution to the model without testing every possible combination, as linear regression might do. It’s like taking a strategic path toward the best model, considering each predictor’s importance along the way.
Let’s now apply LARS to predict US consumer price index (CPI) values.
If you want to see more of my work, you can visit my website for the books catalogue by simply following the link attached the picture:

Predicting Time Series Using LARS
The CPI is a measure used to track changes in the prices of a basket of goods and services purchased by households. It’s one of the most commonly used indicators for inflation, which is the rate at which the general level of prices for goods and services is rising.
Here are the steps we will follow for this experiment:
Import the CPI data using pandas_datareader library as seen below.
Take the difference of the data in order to make it stationary.
Choose the lag and the split ratio. In our case, it will be a lag of 100 and a train-test split ratio of 80% (meaning that the last 20% of the data will be used to test the predictive power of the algorithm).
Split the data into training and test sets (while using lagged values as features or predictors). Fit and predict using the LARS algorithm.
Evaluate the model using the hit ratio measure (also known as accuracy).
✨ Important note
Why make the data stationary? Making the data stationary before forecasting is important because many time series forecasting techniques assume that the underlying data generating process is stationary. Stationarity refers to the statistical properties of a time series remaining constant over time.
Use the following code to implement the experiment:
# Importing libraries
from sklearn import linear_model
import numpy as np
import matplotlib.pyplot as plt
import pandas_datareader as pdr
# Set the start and end dates for the data
start_date = '1980-01-01'
end_date = '2024-02-01'
# Fetch the CPI data
data = np.array((pdr.get_data_fred('CPILFESL', start = start_date, end = end_date)).dropna())
# Difference the data and make it stationary
data = np.diff(data[:, 0])
data = np.diff(data[:])
# Setting the hyperparameters
num_lags = 100
train_test_split = 0.80
def data_preprocessing(data, num_lags, train_test_split):
# Prepare the data for training
x = []
y = []
for i in range(len(data) - num_lags):
x.append(data[i:i + num_lags])
y.append(data[i+ num_lags])
# Convert the data to numpy arrays
x = np.array(x)
y = np.array(y)
# Split the data into training and testing sets
split_index = int(train_test_split * len(x))
x_train = x[:split_index]
y_train = y[:split_index]
x_test = x[split_index:]
y_test = y[split_index:]
return x_train, y_train, x_test, y_test
# Creating the training and test sets
x_train, y_train, x_test, y_test = data_preprocessing(data, num_lags, train_test_split)
model = linear_model.Lars(n_nonzero_coefs = 2)
# Train the model
model.fit(x_train, y_train)
# Predicting out-of-sample
y_pred = np.reshape(model.predict(x_test), (-1))
# Plotting
plt.plot(y_pred[-100:], label='Predicted Data', linestyle='--', marker = '.', color = 'red')
plt.plot(y_test[-100:], label='True Data', marker = '.', alpha = 0.7, color = 'blue')
plt.legend()
plt.grid()
plt.axhline(y = 0, color = 'black', linestyle = '--')
same_sign_count = np.sum(np.sign(y_pred) == np.sign(y_test)) / len(y_test) * 100
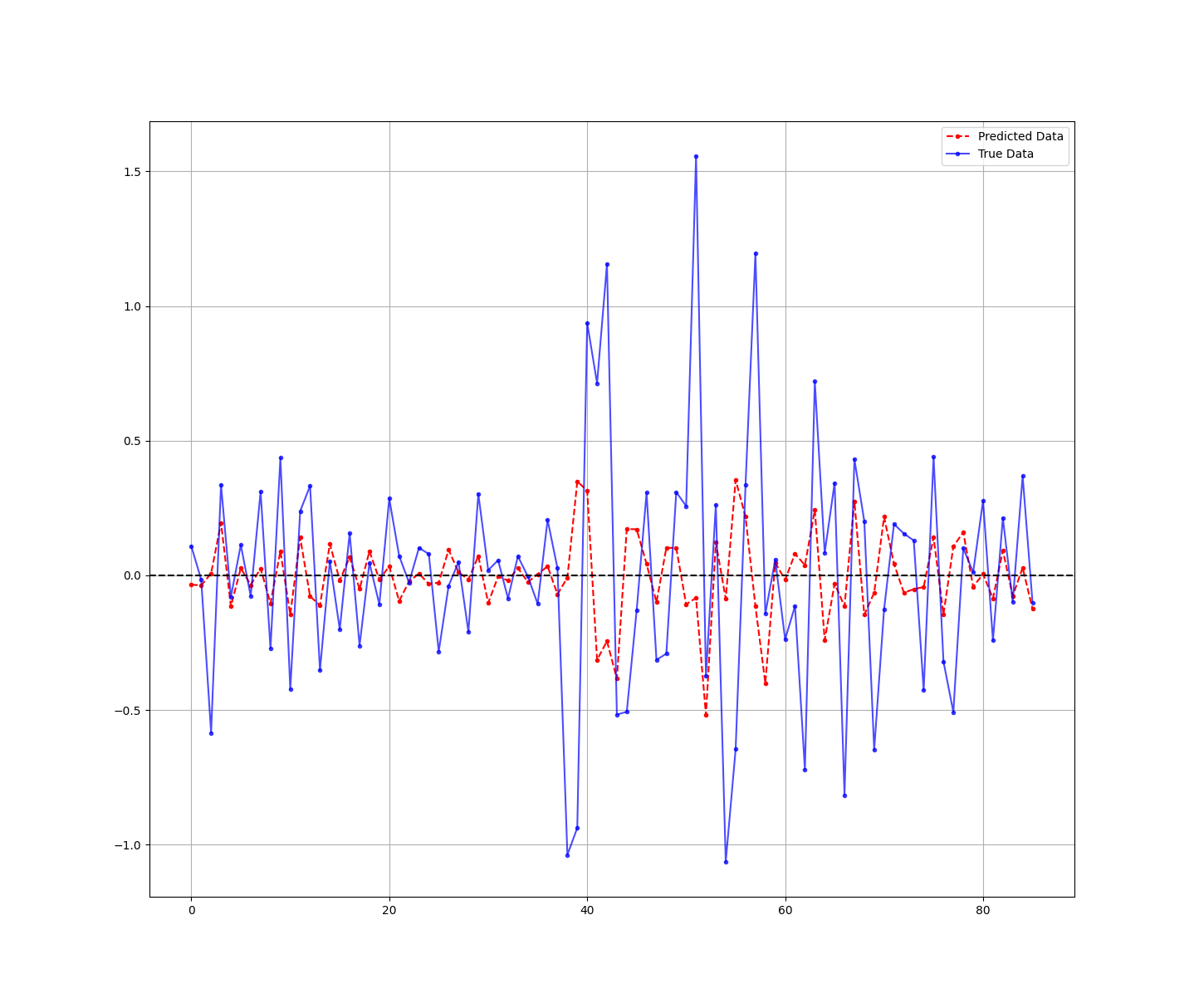
print('Hit Ratio = ', same_sign_count, '%')The following chart shows the predicted data versus the real data:
✨ Important note
The variable n_nonzero_coefsint is the target number of non-zero coefficients. You can use np.inf for no limit.
The output is as follows:
Hit Ratio = 65.11627906976744 %It seems that with an accuracy of 65%, the model seems to be able to predict whether the next change in inflation will be positive or negative. Naturally, more factors must be included to forecast inflation. This was just an example to show you how to use the LARS algorithm.
Evidently, we always need to consider the advantages and disadvantages of any algorithm we use. Let’s start with the advantages:
LARS is computationally efficient, especially when compared to other variable selection methods like stepwise regression. It can handle a large number of predictors efficiently, making it suitable for high-dimensional datasets where traditional methods may struggle.
LARS produces a path of solutions, showing the sequence in which predictors are added to the model.
Unlike some other variable selection methods, LARS tends to be stable when dealing with multicollinearity (high correlation between predictors) and noisy data.
The weaknesses of the model are:
LARS can be sensitive to outliers in the data, particularly when outliers are influential on the estimation of coefficients.
LARS assumes a linear relationship between predictors and the outcome variable. If the true relationship is non-linear, LARS may not capture it accurately, leading to suboptimal predictions.
While LARS helps prevent overfitting by selecting predictors in a stepwise manner, there is still a risk of overfitting if the dataset is small relative to the number of predictors.
You can also check out my other newsletter The Weekly Market Sentiment Report that sends tactical directional views every weekend to highlight the important trading opportunities using a mix between sentiment analysis (COT reports, Put-Call ratio, Gamma exposure index, etc.) and technical analysis.