


Risk management is even more important than the strategy itself. It is the part of trading that protects you from you. Many variables in the markets are against us and the only shield we have is our risk management and hence we need to take good care of it. This article outlines the main points and gives some tips on how to manage risk.
The Concept of Risk
Risk and reward are the two main pillars of financial markets. We love reward but dislike risk.
Therefore, the primary function when trading and investing is to maximize reward (Returns) and minimize risk (Volatility and other forms of risk). However, we need to understand that the two go hand-in-hand and there is no reward with no risk. It is simply a premium we have to pay to benefit from the reward, we only have to make sure that we have enough sound judgement that allows us to select the right rewards while benefitting from low risk.
Risk can be categorized in many ways such as market risk, operational risk, credit risk, pin risk, and others. The one we are interested in is mostly volatility and the risk of losing on a trade. This can be minimized by making a certain set of rules that act as a fool-proof. Below are some concepts of risk and how to manage it well.
You can also check out my other newsletter The Weekly Market Sentiment Report that sends tactical directional views every weekend to highlight the important trading opportunities using a mix between sentiment analysis (COT reports, Put-Call ratio, Gamma exposure index, etc.) and technical analysis.
Managing Volatility
Volatility is a key concept in finance, whoever masters it holds a tremendous edge in the markets. Unfortunately, we cannot always measure and predict it with accuracy. Even though the concept is more important in options trading, we need it pretty much everywhere else. Traders cannot trade without volatility nor manage their positions and risk. Quantitative analysts and risk managers require volatility to be able to do their work. Before we discuss the different types of volatility, why not look at a graph that sums up the concept? Check out the below image to get you started.
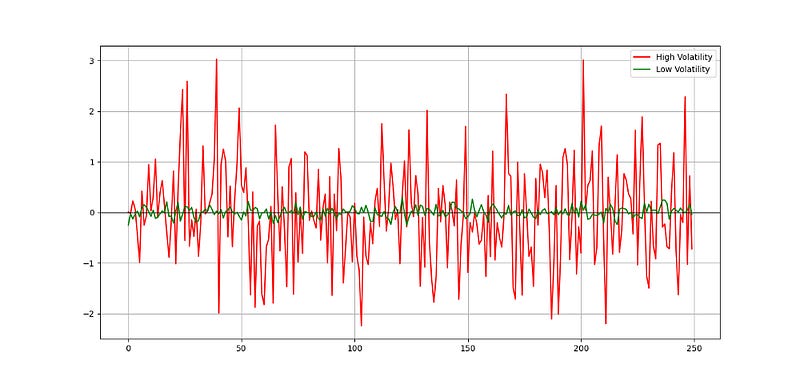
You can code the above in Python yourself using the following snippet:
# Importing the necessary libraries
import numpy as np
import matplotlib.pyplot as plt
# Creating high volatility noise
hv_noise = np.random.normal(0, 1, 250)
# Creating low volatility noise
lv_noise = np.random.normal(0, 0.1, 250)
# Plotting
plt.plot(hv_noise, color = 'red', linewidth = 1.5, label = 'High Volatility')
plt.plot(lv_noise, color = 'green', linewidth = 1.5, label = 'Low Volatility')
plt.axhline(y = 0, color = 'black', linewidth = 1)
plt.grid()
plt.legend()The different types of volatility around us can be summed up in the following:
Historical volatility: It is the realized volatility over a certain period of time. Even though it is backward looking, historical volatility is used more often than not as an expectation of future volatility due to the clustering phenomenon.
Implied volatility: In its simplest definition, implied volatility is the measure that when inputted into the Black-Scholes equation, gives out the option’s market price. It is considered as the expected future actual volatility by market participants. It has one time scale, the option’s expiration.
Forward volatility: It is the volatility over a specific period in the future.
Actual volatility: It is the amount of volatility at any given time. Also known as local volatility, this measure is hard to calculate and has no time scale.
The most basic type of volatility is our old friend “the Standard Deviation”. It is one of the pillars of descriptive statistics and an important element in some technical indicators (such as the Bollinger Bands). But first let us define what variance is before we find Standard Deviation:
Variance is the squared deviations from the mean (a dispersion measure), we take the square deviations so as to force the distance from the mean to be non-negative, finally we take the square root to make the measure have the same units as the mean, in a way we are comparing apples to apples (mean to standard deviation standard deviation). Variance is calculated through this formula:

Following our logic, standard deviation is therefore:
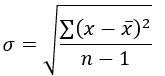
Therefore, if we want to understand the concept in layman’s terms, we can say that Standard Deviation is the average distance away from the mean that we expect to find when we analyze the different components of the time series.
We can manage volatility by including it in our stops and targets. For this, we can use the famous Average True Range Indicator. Although it is considered as a lagging indicator, it gives some insights as to where volatility is now and where has it been last period (day, week, month, etc.).
But first, we should understand how the True Range is calculated (the ATR is just the average of that calculation). Consider an OHLC data composed of an timely arrange Open, High, Low, and Close prices. For each time period (bar), the true range is simply the greatest of the three price differences:
High — Low
High — Previous close
Previous close — Low
Once we have got the maximum out of the above three, we simply take a smoothed average of n periods of the true ranges to get the Average True Range. Generally, since in periods of panic and price depreciation we see volatility go up, the ATR will most likely trend higher during these periods, similarly in times of steady uptrends or downtrends, the ATR will tend to go lower. One should always remember that this indicator is very lagging and therefore has to be used with extreme caution.
Since it has been created by Wilder Wiles, also the creator of the Relative Strength Index, it uses Wilder’s own type of moving average, the smoothed kind. To simplify things, the smoothed moving average can be found through a simple transformation of the exponential moving average.
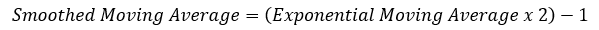
The above formula means that a 100 smoothed moving average is the same thing as (100 x 2) -1 = 199 exponential moving average.

How is this indicator used in setting stops and targets? Well, the algorithm may follow these rules.
A long (Buy) position:
The algorithm initiates a buy order after a signal has been generated following a certain strategy.
Then, the algorithm will monitor the ticks and whenever the high equals a certain constant multiplied by ATR value at the time of the trade inception, an exit (at profit) order is initiated. Simultaneously, if a low equals a certain constant multiplied by ATR value at the time of the trade inception is seen, an exit (at loss) is initiated. The exit encountered first is naturally the taken event.
A short (Sell) position:
The algorithm initiates a short sell order after a signal has been generated following a certain strategy.
Then, the algorithm will monitor the ticks and whenever the low equals a certain constant multiplied by ATR value at the time of the trade inception, an exit (at profit) order is initiated. Simultaneously, if a high equals a certain constant multiplied by ATR value at the time of the trade inception is seen, an exit (at loss) is initiated. The exit encountered first is naturally the taken event.
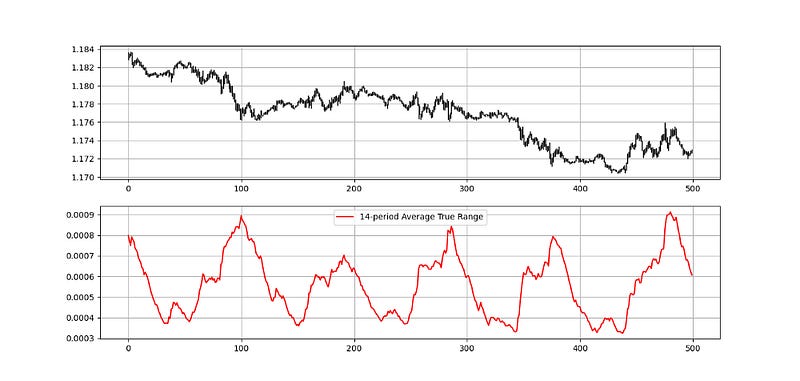
The plot above shows the Average True Range. Take a look at the latest value on the ATR. It is around 0.0006 (6 pips). If we initiate a buy order following a simple 2.00 risk-reward ratio (risking half of what we expect to gain), we can place an order this way:
Buy at current market price.
Take profit at current market price + (2 x 6 pips).
Stop the position at current market price — (1 x 6 pips).
The Average True Range Indicator is a key pillar when dealing with volatility. It is one way to measure it and is followed by many market participants thus, giving it more strength. The biggest utility of the indicator is as described above, risk management and placing stops/targets. You can set your expected (theoretical) risk-reward ratio from your trades by setting the parameters on the indicator. For example, the multiplication example we have seen should give us a theoretical risk-reward ratio of 2.00.
Managing Emotions
Do you believe that every investor in the world has access to perfect information, perfect timing, and the absolute skill to deal with the information in the correct way?
I’m betting on no. Whenever there is money to be made, irrationality looms around. Behavioral finance tries to explain some phenomena we see every day in the markets. It presents some biases that seem to inflict most of us due to our human nature and that is one of the reasons that robots are doing the trading now. Basically, biases are divided into two parts, cognitive and emotional, with the former dealing with judgement mistakes and the latter with emotional slips. Understanding these biases will be crucial to knowing how to set risk management rules.
Starting with cognitive biases we can discuss the most common ones to keep in mind:
Conservatism is when a trader is slow to react to new information and places too much weight on base rates. The way to deal with this bias to force one’s self to be skeptical of her basic analysis and to be always dynamic and ready for change. The market does not look too far into the past.
Confirmation bias is when the trader focuses on positive information and dismisses negative information. This is by far one of the most common ones and it is actually a normal state of mind that leads to overconfidence. By positive information, I mean the ones that seem to support the trader’s initial view. So, if the trader is bullish, she will only look at positive news on the stock and disregard any bad news on the company.
Representativeness is where the inflicted is very fast to react on new information with no regard to past information. The key here is to balance the decision-making process and to try to objectify it as much as possible.
Illusion of control bias can lead to concentrated positions due to a sense of power over the invested asset. It can be due to a weak liquidity stock. This tends to be more common with penny stocks rather than enormous markets such as FX and commodities.
Hindsight bias makes the inflicted overestimate her past accuracy and can lead to excessive risk taking. The majority of predictions are made with hindsight. This means that we can all look at past charts and conclude that the future direction was to predict. Most back-tests also suffer from what is known as look-ahead bias which is the hindsight equivalent of a systematic machine strategy. It is simply defined as the fact of including data that happened after the prediction point making it unrealistic.
Anchoring bias is where one does not change his original forecast or research even when new information comes out. As I have mentioned, the analyst or trader must always be dynamic. After all, the market is always dynamic and changing properties.
Mental accounting bias is when investors construct layered portfolios and suffer from suboptimal diversification due to a lack of consideration for the correlations. It can be tempting to construct a segmented portfolio but from a portfolio management point of view, this hurts more than it helps.
Availability bias is about selecting investments based on how easily their memories are retrieved. In other words, full due-diligence should be ensured at every step so as not to miss-out on interesting opportunities.

Emotional biases on the other hand are purely psychological and do not stem from poor judgement.
Loss aversion is by far the most common emotional bias that exists and it is the act of cutting gains too soon and losses too late out of fear of missing out. The best way to remedy this is to stick to a fixed risk-reward ratio and to automate the position-closing mechanism.
Overconfidence means holding concentrated positions and results in trading excessively. A good streak does not mean that it will always be the case and thus, the trader must always follow procedures and ensure he does not stray from the strategy.
Self-control bias refers to a lack of discipline to balance short-term gratification with long-term goals.
Regret-aversion refers to staying in low-risk investment out of fear. This really is all about the risk profile of the trader. There is no right or wrong answer here but the fear of regret can make the trader lose out on interesting opportunities. One should take risks to make money.
It seems that algorithmic trading solves many of these issues. This also means that compared to manual trading, algorithmic trading ups the ante with regards to risk management. The key from this section is to incorporate as much biases as possible into you risk system. Here are a few examples:
Self-Control is fixed by an algorithm that follows specific rules and does not rely on subjective opinions.
Loss Aversion is eliminated as the algorithm automatically closes and opens the position with no fear or greed.
Managing Correlations
The markets are related to one another and this is an undisputed fact that even across different asset classes, we must keep in mind that correlations can give us clues as to whether we should initiate the position, hedge, or even stay away from it.
Correlation across different assets and markets is crucial to determine any directional bias and trigger for a trade. If we have a buy signal on one asset and a sell signal on another, but yet they are almost perfectly correlated then we know that one of the signals is wrong because empirically, we have the information that they move together in the same direction. Correlation management is part of risk management and is an important part in it.
Correlation is the degree of linear relationship between two or more variables. It is bounded between -1 and 1 with one being a perfectly positive correlation, -1 being a perfectly negative correlation, and 0 as an indication of no linear relationship between the variables (they relatively go in random directions). The measure is not perfect and can be biased by outliers and non-linear relationships, it does however provide quick glances to statistical properties. Two famous types of correlation exist and are commonly used:
Spearman correlation measures the relationship between two continuous or ordinal variables. Variables may tend to change together, but not necessarily at a constant rate. It is based on the ranks of values rather than the raw data.
Pearson correlation measures the linear relationship between two continuous variables. A relationship can be considered linear when a change in one is accompanied with a proportional change in the other.
The measure is not perfect and can be biased by outliers and non-linear relationships, it does however provide quick glances to statistical properties.

When we have a certain bias on a currency pair such as the USDCAD pair, we need to keep in mind what other assets are related to it. One thing comes to mind when speaking about the Canadian Dollar and it is Petrol. Therefore, the correlation between USDCAD and Crude Oil is extremely important.
Let us say you analyze both charts and see they are both lying on an implied support you have found (Based on your own judgement). Does it make sense to go ahead and trade them knowing that they are showing the same signal? Naturally they should move in opposite direction, so which one is really lying on support?
These kinds of incoherent situations should alert us to the fact that there might be more risk in the trade than we have thought.
Managing Position Sizing
Position sizing is also very important as not all trades have the same degree of conviction and risk. This is why we need an objective measure to size our positions. Many people have their own models, be that objective (Based on facts and numbers) or subjective (Based on conviction).
Objective position sizing: This is based on numerical models or formulas so as to automate the process and makes it relative on other factors. This is the best way of approaching position sizing.
Subjective position sizing: This is based on the feeling or the conviction of the trader. This is not very optimal as it biases performance evaluation at the end and makes it more complicated. Also, it is not consistent as the human judgement is subjective to many random variables.
Equal position sizing: This assumes the same size for all positions. It is a standard method that is neither optimized neither subjective. It can be considered as the middle ground between objectivity and subjectivity.
One method I may suggest is the Hit Ratio method. This method is based on the momentum of the recent successful trades. Imagine you have a contrarian strategy based on ranging markets. If we see a rise in the Hit Ratio (i.e. more trades are profitable recently), then we might assume that the market regime is favorable and we can assume that it will persist for a while, therefore, increasing our position size by using the values given by our Hit Ratio. When the strategy starts to underperform, the technique will take this into account by lowering the size. Here is an example:
The ten first trades will have a standard lot size such as 1 contract or $100,000.
As of trade number 11, we will calculate the hit ratio of the first ten trades. Let us assume that the hit ratio is 70%. Therefore, we will enter at 0.7 of a contract or $70,000.
Trade number 12 will incorporate the rolling 10-period Hit Ratio. Let us suppose that trade number 11 was a winner and trade number 1 was a loser. Therefore, the rolling 10-period Hit Ratio will be 80% and we can enter at 0.8 of a contract or $80,000.
Finally, we can form a rule on where we have 10 consecutive losing trades. Since this will mathematically give us a position size of zero, we can set a threshold or simply abandon the strategy. It is up to us to customize it. We can also use another period other than 10.
You can also check out my other newsletter The Weekly Market Analysis Report that sends tactical directional views every weekend to highlight the important trading opportunities using technical analysis that stem from modern indicators. The newsletter is free.
If you liked this article, do not hesitate to like and comment, to further the discussion!