
Purging and Embargo - Two Tricks That Stop Time Series Models From Lying to You
Understand These Two Important Concepts in Time Series Forecasting


If you’ve ever built a model on time series data (prices, traffic, sales, sensor readings, user activity) and felt that the backtest looked too good, there’s a decent chance you accidentally let the future leak into the past.
It usually doesn’t look like cheating. It looks like a normal train/test split.
But in time series, the shape of your split matters as much as the split itself.
Two simple ideas help a lot:
Purging: remove training samples that are “too close” to the test period and still overlap it through labeling or feature windows.
Embargo: create a safety buffer around test periods so that adjacent periods don’t contaminate each other when you run multiple folds (or when your data has slow-moving effects).
These concepts show up most often in financial ML, but they apply to any time-ordered prediction where your features or labels have temporal overlap.
Let’s make this concrete, then we’ll build a tiny sine-wave predictor and plot exactly what gets purged and embargoed.
The Real Problem: Overlap You Can’t See
A classic supervised dataset assumes each row is independent:
Row
iuses featuresX_iRow
ihas labely_iRows don’t “touch” each other
Time series breaks that assumption immediately.
1) Your Features are Windows
Instead of one observation, you often use a lookback window:
features at time
t= values fromt-L+1 ... t
So rows overlap in their inputs.
2) Your Labels May be Forward-Looking
Often you predict a horizon ahead:
label at time
tmight be the value att+H
So the “ownership” of a timestamp becomes fuzzy:
a single timestamp can appear inside many rows’ feature windows
and labels can be close enough to overlap boundaries
This overlap becomes deadly when you split data.
Leakage in One Sentence
Leakage happens when your training set contains information that wouldn’t be available at prediction time for your test set.
In time series, that can happen even if you split chronologically.
Why? Because “chronologically” doesn’t automatically mean “non-overlapping.”
If your last training sample uses a window that touches the start of the test period (or its label lands inside the test period), the model is getting an unfair hint.
Purging: What it is and Why it Exists
Purging means removing training examples whose label time (or window) overlaps the test region. The most common version is this:
You define a test period:
t ∈ [T_start, T_end]You remove any training samples whose label timestamp falls inside that interval
This matters when labels are defined over an interval (like returns over a holding period), or whenever the label is tied to a future point (t+H) that can land inside the test window even if the feature time t is earlier.
Purging in plain language
“If a training row is still ‘connected’ to the test period through the way we built labels/features, drop it.”
Embargo: The Buffer that Prevents Edge Contamination
Embargo means imposing a time buffer around the test period so that data near the boundary can’t sneak information across folds.
This is especially important in cross-validation over time.
Imagine you do multiple folds like this:
Fold 1 tests on Jan
Fold 2 tests on Feb
Fold 3 tests on Mar
If your features include rolling windows and your target horizon is forward-looking, then training for Fold 2 might include data immediately after the Fold 1 test window, and those points can still be influenced by the events in Fold 1’s test period (or vice versa).
Embargo says:
“After a test window ends (or around it), don’t allow nearby data to appear in training for adjacent folds.”
Even if you only do one split, embargo is a useful way to visually communicate: “We intentionally left a safety gap.”
When Do You Actually Need These?
You should seriously consider purging/embargo when any of these are true:
You use rolling windows (moving averages, lag features, technical indicators, rolling normalization).
Your label uses a future horizon (predict
t+H, future return, future demand).Your label spans an interval (return from
ttot+H, max drawdown over next week, etc.).Your process has slow spillover (marketing campaigns, delayed sensor effects, volatility clustering, user retention).
If your data is truly point-in-time and non-overlapping (rare in time series), you can be simpler. But most real pipelines overlap.
Purging and embargo reduce the amount of training data. That’s the point.
You’re trading more samples for a backtest you can trust.
If your metrics drop, that’s not “worse.” That’s “less delusional.”
Stop Guessing. Start Trading with The Signal Beyond report 🚀
COT Data • Technical charts • Equity Arbitrage • Seasonality
A Minimal Example: Predicting a Sine Wave With Purging and Embargo
Below is a small, readable Python script that:
Generates a sine wave with noise
Builds a supervised learning dataset using a lookback window
Splits into Train / Purge Gap / Test / Embargo Gap
Fits a simple linear model (least squares)
import numpy as np
import matplotlib.pyplot as plt
rng = np.random.default_rng(7)
N = 1000
t = np.arange(N)
y = np.sin(2 * np.pi * t / 80) + 0.15 * rng.standard_normal(N)
L = 30 # lookback window length (features)
H = 1 # forecast horizon
X = []
Y = []
time_of_label = [] # the timestamp of the label y[t+H]
time_of_feature_end = [] # the timestamp t (end of feature window)
for feature_end in range(L - 1, N - H):
x = y[feature_end - L + 1 : feature_end + 1] # length L
target = y[feature_end + H]
X.append(x)
Y.append(target)
time_of_feature_end.append(feature_end)
time_of_label.append(feature_end + H)
X = np.asarray(X) # shape: (n_samples, L)
Y = np.asarray(Y) # shape: (n_samples,)
time_of_feature_end = np.asarray(time_of_feature_end)
time_of_label = np.asarray(time_of_label)
# We choose a test window in terms of original time index.
test_start_time = 520
test_end_time = 680 # exclusive end
purge_len = L + H - 1 # a simple, conservative choice
embargo_len = 30
# Training ends BEFORE the purge gap
train_end_time = test_start_time - purge_len
# Embargo region is after the test window
embargo_start_time = test_end_time
embargo_end_time = min(N, test_end_time + embargo_len)
# Build boolean masks for samples based on label timestamps (simplest to reason about)
is_train = time_of_label < train_end_time
is_test = (time_of_label >= test_start_time) & (time_of_label < test_end_time)
# (Optional) mark samples that fall in the purge gap or embargo gap, for clarity
is_purge_gap = (time_of_label >= train_end_time) & (time_of_label < test_start_time)
is_embargo_gap = (time_of_label >= embargo_start_time) & (time_of_label < embargo_end_time)
X_train, Y_train = X[is_train], Y[is_train]
X_test, Y_test = X[is_test], Y[is_test]
def fit_linear_regression(Xm, ym):
# add intercept column
A = np.column_stack([np.ones(len(Xm)), Xm])
# solve (A^T A) w = A^T y
w, *_ = np.linalg.lstsq(A, ym, rcond=None)
return w
def predict_linear_regression(Xm, w):
A = np.column_stack([np.ones(len(Xm)), Xm])
return A @ w
w = fit_linear_regression(X_train, Y_train)
Y_pred_test = predict_linear_regression(X_test, w)
# Map predictions back to original time indices (label times)
test_label_times = time_of_label[is_test]
plt.figure(figsize=(12, 5))
plt.plot(t, y, linewidth=1, label="True series")
# Shade regions (no manual colors; matplotlib will choose defaults)
plt.axvspan(0, train_end_time, color = 'red', alpha=0.15, label="Training region (used)")
plt.axvspan(train_end_time, test_start_time, color = 'black',alpha=0.15, label="Purging gap (not used)")
plt.axvspan(test_start_time, test_end_time, color = 'green',alpha=0.15, label="Test region (evaluated)")
plt.axvspan(embargo_start_time, embargo_end_time, color = 'orange',alpha=0.15, label="Embargo gap (not used)")
# Plot predictions over the test label times
plt.plot(test_label_times, Y_pred_test, linewidth=2, label="Model prediction (test)")
plt.title("Sine-wave forecasting with Purging + Embargo")
plt.xlabel("Time index")
plt.ylabel("Value")
plt.legend(loc="upper right")
plt.tight_layout()
plt.show()
# Simple numeric evaluation on the test window
mse = np.mean((Y_pred_test - Y_test) ** 2)
print(f"Test MSE: {mse:.6f}")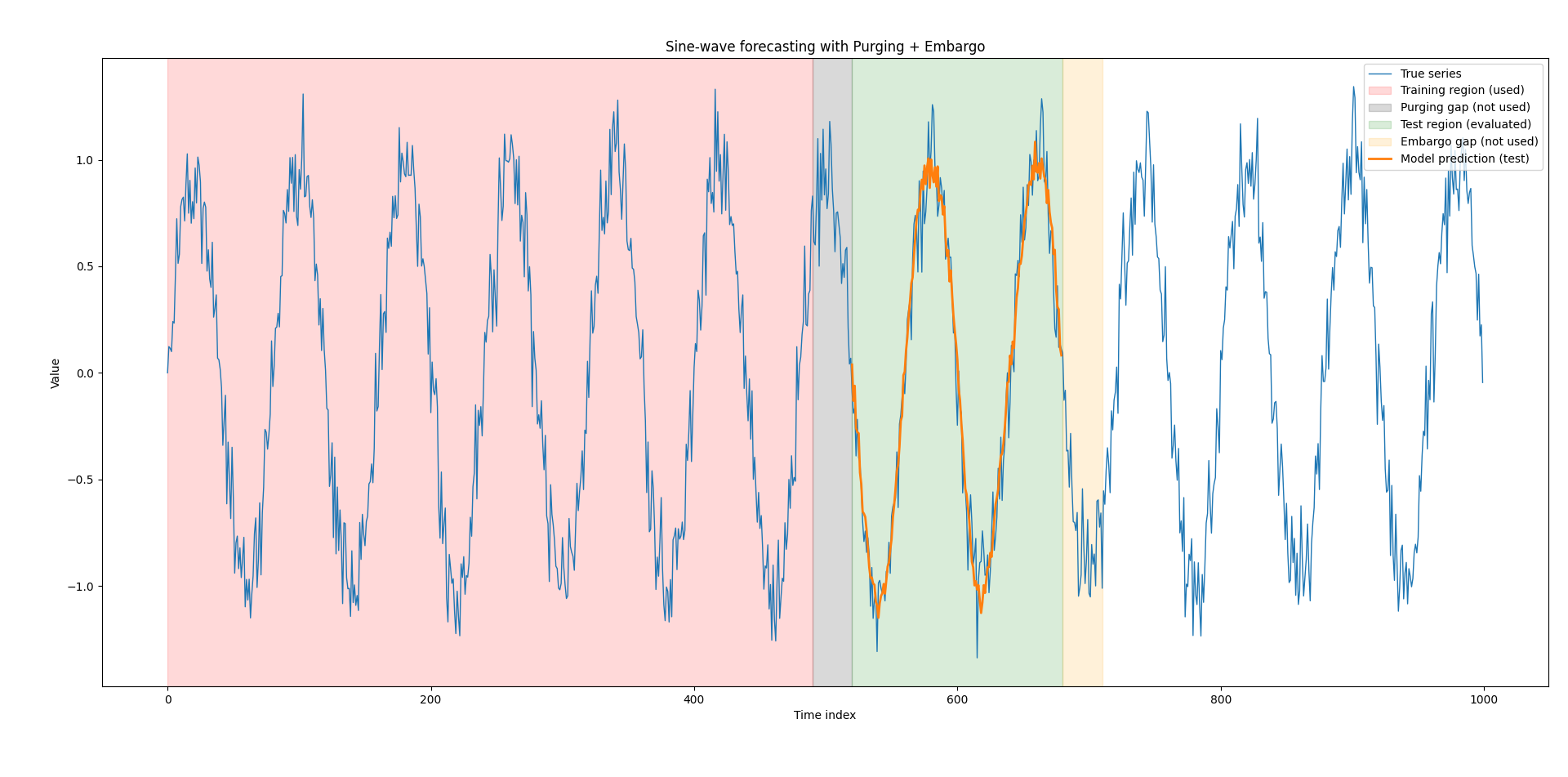
What this example illustrates
Purging gap sits between training and test so that the last training rows don’t share a window edge with the test start.
Embargo gap sits after the test window to show a safety buffer (useful when you chain folds or reuse data later).
Even if the sine wave is simple, the splitting logic is the real lesson.
Master Deep Learning techniques tailored for time series and market analysis🔥
My book breaks it all down from basic machine learning to complex multi-period LSTM forecasting while going through concepts such as fractional differentiation and forecasting thresholds. Get your copy here 📖!