
Machine Learning in Fundamental Analysis
Using Python to Perform Machine Learning Tasks on Fundamental Data

Machine learning is rapidly becoming the main engine of financial predictions as developers and traders rush to harness its limitless capabilities to analyze complex data. This article shows how to code a simple linear regression model to predict the price-to-sales ratio using financial metrics acquired from FMP.
Quick Introduction to Machine Learning for Time Series
Machine learning is like teaching a computer to play that game by showing it examples of gameplay and letting it figure out the rules on its own.
There are different types of machine learning, but let’s focus on the big one: supervised learning. This is like having a teacher guide you through the game. You give the computer examples of inputs (like the moves you make in the game) and outputs (like the score you get or whether you win or lose). The computer then learns from these examples to make predictions or decisions on its own.
Linear regression is just one tool in the machine learning toolbox. It’s like teaching the computer to draw a straight line through scattered points on a graph, as we discussed earlier. But there are many other tools, like decision trees, support vector machines, and neural networks.
Each of these tools has its strengths and weaknesses, kind of like different strategies you might use in different parts of the video game. Some might be better at handling complex patterns, while others might be simpler but faster to use.
The goal of machine learning is to train the computer to make accurate predictions or decisions based on new data it hasn’t seen before. Just like how you get better at the video game the more you play, the computer gets better at its task the more examples you give it and the more it learns from them.
We can use this tool to try to predict some financial and economic variables in the hopes of having a better vision for the future of certain stocks. We will use the variables from Financial Modelling Prep (FMP).
Quick Introduction to FMP
Financial Modeling Prep (FMP) API provides real time stock price, company financial statements, major index prices, stock historical data, forex real time rate and cryptocurrencies.
FMP stock price API is in real time, the company reports can be found in quarter or annual format, and goes up to 30 years back in history. This article will show one way to use the API to import key financial metrics and evaluate them using theoretical financial analysis.
Predicting Price-to-Sales Data Using Linear Regression
Imagine you’re trying to predict something cool, like how much money you’ll have in your piggy bank at the end of the month. Now, let’s say you want to know if there’s a relationship between how much money you put in your piggy bank and how many chores you do around the house.
Now, you gather data for a few months. You record how much money you put in your piggy bank and how many chores you did. Then, you plot those points on a graph. Linear regression helps you find the best-fitting line through those points. This line gives you a simple way to estimate how much money you’ll have in your piggy bank based on how many chores you do.
So, if you do more chores, the line predicts you’ll have more money in your piggy bank. If you do fewer chores, the line predicts you’ll have less money. It’s not a perfect prediction, but it gives you a good idea of what to expect based on the pattern you see in your data. And that’s the basics of linear regression in financial time series — finding relationships between variables and using them to make predictions. Let’s see how to do this in Python.
Use the following code to create the experiment using these conditions:
Import the quarterly price-to-sales ratio of Apple using the API key you get when you sign up.
Calculate the change (positive or negative) of the ratio from one quarter to another.
Split the historical data using a 75%/25% ratio where 75% of the data is used for training and 25% is used for testing.
Evaluate the performance using the accuracy metric.
#!/usr/bin/env python
try:
# For Python 3.0 and later
from urllib.request import urlopen
except ImportError:
# Fall back to Python 2's urllib2
from urllib2 import urlopen
import certifi
import json
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
def get_jsonparsed_data(url):
"""
Receive the content of ``url``, parse it as JSON and return the object.
Parameters
----------
url : str
Returns
-------
dict
"""
response = urlopen(url, cafile=certifi.where())
data = response.read().decode("utf-8")
return json.loads(data)
url_1 = ("https://financialmodelingprep.com/api/v3/ratios/AAPL?period=quarter&apikey=YOUR_API_KEY_HERE")
ratios = get_jsonparsed_data(url_1)
ps = []
for dictionary in ratios:
if 'priceSalesRatio' in dictionary:
ps.append(dictionary['priceEarningsRatio'])
ps = ps[::-1]
ps = pd.Series(ps[17:]) # to remove the first zero values
ps.describe()
def data_preprocessing(data, num_lags, train_test_split):
# Prepare the data for training
x = []
y = []
for i in range(len(data) - num_lags):
x.append(data[i:i + num_lags])
y.append(data[i+ num_lags])
# Convert the data to numpy arrays
x = np.array(x)
y = np.array(y)
# Split the data into training and testing sets
split_index = int(train_test_split * len(x))
x_train = x[:split_index]
y_train = y[:split_index]
x_test = x[split_index:]
y_test = y[split_index:]
return x_train, y_train, x_test, y_test
def calculate_accuracy(predicted_returns, real_returns):
predicted_returns = np.reshape(predicted_returns, (-1, 1))
real_returns = np.reshape(real_returns, (-1, 1))
hits = sum((np.sign(predicted_returns)) == np.sign(real_returns))
total_samples = len(predicted_returns)
accuracy = hits / total_samples
return accuracy[0] * 100
from sklearn.linear_model import LinearRegression
data = ps
data = np.diff(data)
# Setting the hyperparameters
num_lags = 6
train_test_split = 0.75
# Creating the training and test sets
x_train, y_train, x_test, y_test = data_preprocessing(data, num_lags, train_test_split)
# Fitting the model
model = LinearRegression()
model.fit(x_train, y_train)
# Predicting in-sample
y_predicted_train = np.reshape(model.predict(x_train), (-1, 1))
# Predicting out-of-sample
y_predicted = np.reshape(model.predict(x_test), (-1, 1))
# plotting
y_test = np.reshape(y_test, (-1, 1))
y_train = np.reshape(y_train, (-1, 1))
'''plt.plot(y_train, label = 'Y_Train')
plt.plot(y_predicted_train, label = 'In-Sample Predictions')
plt.axhline(y = 0, color = 'black')
plt.grid()
plt.legend()'''
plt.plot(y_test, label = 'Y_Test')
plt.plot(y_predicted, label = 'Out-of-Sample Predictions')
plt.axhline(y = 0, color = 'black')
plt.grid()
plt.legend()
# Performance evaluation
print('---')
print('Accuracy Train = ', round(calculate_accuracy(y_predicted_train, y_train), 2), '%')
print('Accuracy Test = ', round(calculate_accuracy(y_predicted, y_test), 2), '%')
print('---')You have to create an account and get your API key and replace it in the appropriate place in the previous code. I highly recommend this as it takes no longer than a few minutes.
Link for the FMP site here.
Financial Modeling Prep - FinancialModelingPrep
FMP offers a stock market data API covers real-time stock prices, historical prices and market news to stock…intelligence.financialmodelingprep.com
The following chart shows the change in the price-to-sales ratio.

On a side note, the price-to-sales (P/S) ratio is a financial metric used to evaluate a company’s stock price relative to its revenue. It is calculated by dividing the market capitalization of the company by its total revenue over a specific period (usually the past 12 months). The P/S ratio provides insight into how much investors are willing to pay for each dollar of a company’s revenue.
A higher P/S ratio indicates that investors are willing to pay more for each dollar of sales, which may suggest that the company is expected to grow its revenue in the future or that investors have high expectations for the company’s performance.
Conversely, a lower P/S ratio may indicate that the company’s stock is undervalued relative to its revenue.
The following chart shows the predicted versus real data in the in-sample set.
The in-sample set, also known as the training set, is the portion of the data that we use to train our model. This set contains examples of input data along with their corresponding correct outputs or labels. The model learns from these examples to make predictions or decisions.

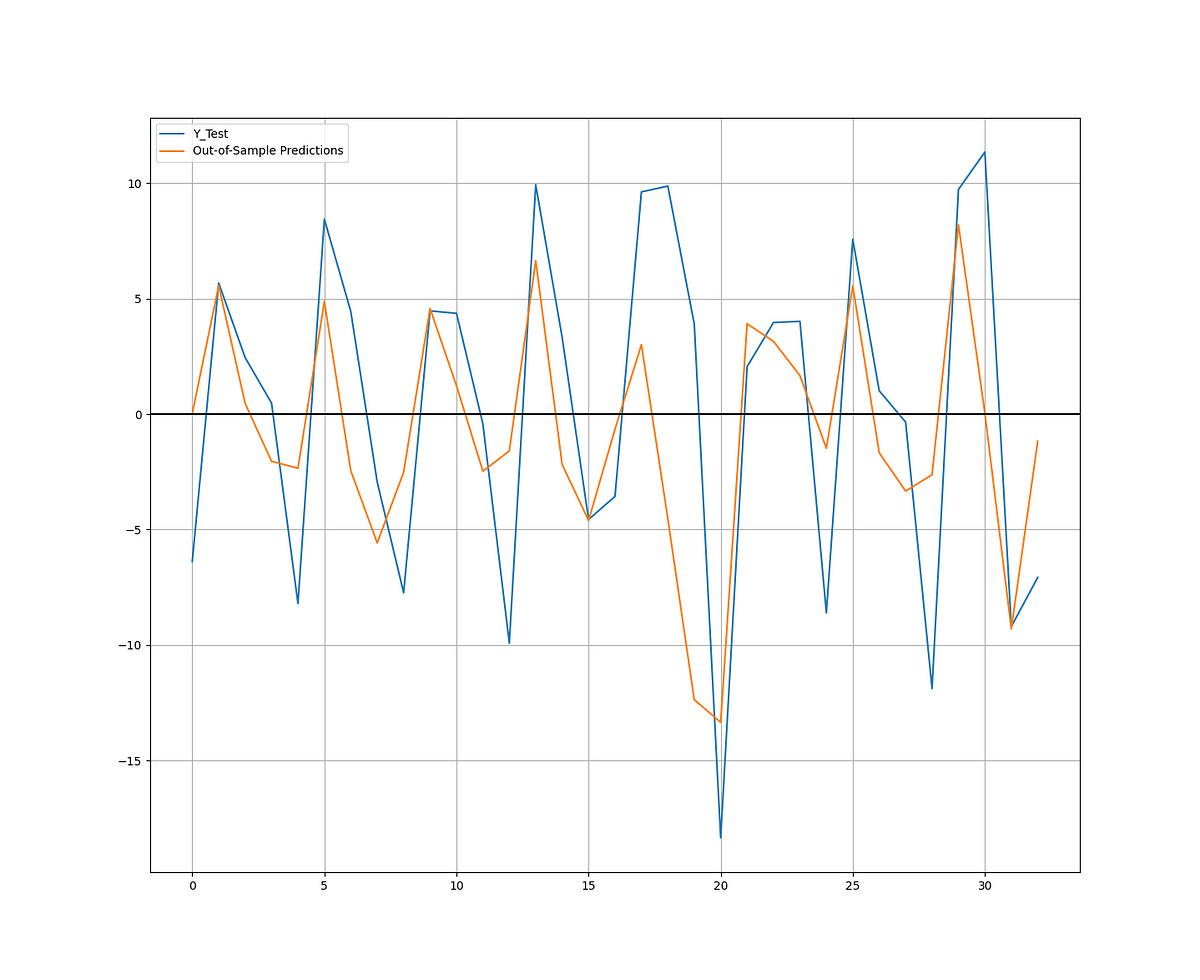
It is worth noting that the data seems to contain outliers which may distort the analysis. You can try to remove them and perform the regression just to see the difference. The following chart shows the predicted versus real data in the out-of-sample set.
The out-of-sample set, also known as the testing set, is a separate portion of the data that the model hasn’t seen during training. This set is used to evaluate how well the model generalizes to new, unseen data. We use the trained model to make predictions on the out-of-sample set, and then compare those predictions to the actual correct outputs or labels to assess the model’s performance.
Financial Modeling Prep - FinancialModelingPrep
FMP offers a stock market data API covers real-time stock prices, historical prices and market news to stock…intelligence.financialmodelingprep.com
The performance of the model is as follows:
Accuracy Train = 73.2 %
Accuracy Test = 78.79 %In a rare occurrence, the testing set as performed better than the training set. When testing data performs better than training data in machine learning, it’s a bit unusual and can signal a few different things.
Firstly, it might indicate that there’s something off with how the data was split or how the model was trained. Normally, you’d expect the model to perform better on the data it was trained on (training data) compared to data it hasn’t seen before (testing data). If the testing data performs better, it might suggest that the model is overfitting the training data.
Overfitting happens when the model learns the training data too well, including its noise and random fluctuations. This can cause the model to perform poorly on new, unseen data because it’s essentially memorizing the training examples rather than learning the underlying patterns. If the testing data performs better, it could mean that the model is generalizing better to new data, which is what you ultimately want.
Lastly, it’s possible that the testing data truly does represent the underlying patterns in the data better than the training data. This could happen if the training data is somehow biased or not fully representative of the population you’re trying to model. In this case, the testing data might provide a more accurate assessment of the model’s performance.
You can also check out my other newsletter The Weekly Market Analysis Report that sends tactical directional views every weekend to highlight the important trading opportunities using technical analysis that stem from modern indicators. The newsletter is free.
If you liked this article, do not hesitate to like and comment, to further the discussion!