


Generative AI involves systems that can create new financial data or insights based on patterns they’ve learned from existing data.
Imagine it like this: you have a smart computer that learns from tons of historical financial data, like stock prices, market trends, and economic indicators. It then uses this knowledge to generate predictions or even create new financial scenarios.
Generative Models and Variational Autoencoders
Generative models are made to produce data that resembles a specified dataset. These models can generate new samples that are statistically similar to the training data by learning the underlying patterns, statistical distributions, or structures present in the data. Applications for generative models include data augmentation, text generation, and image generation.
Generative models include variational autoencoders (VAE). It is a probabilistic and generative model that adds encoding and decoding to the idea of conventional autoencoders. The following is how VAEs carry out their duties:
An input data point is passed via the encoder, which converts it to a probability distribution in a smaller latent space. You may think of the encoder as a recognition network. It comprises of one or more neural network layers that translate the input data into vectors representing the mean and variance of a multivariate Gaussian distribution and the parameters of that distribution in latent space.
Data is then represented in what is known as the latent space. The latent space captures the underlying structure of the data. Instead of directly sampling from the Gaussian distribution in the latent space, the VAE samples from a standard Gaussian distribution (with mean 0 and variance 1) and then scales and shifts the samples using the mean and variance from the encoder.
The latent space is then used to represent the data. The underlying structure of the data is captured by the latent space. The VAE samples from a conventional Gaussian distribution (with mean 0 and variance 1) instead of directly taking samples from the Gaussian distribution in the latent space. The samples are then scaled and shifted using the mean and variance from the encoder.
A loss function must be minimized as part of the VAE’s training process, as is typical of many machine and deep learning models.
After being trained, the VAE can produce fresh data by selecting samples from the latent space and running them through the decoder. In other words, it produces data that resembles the actual data.
You could wonder what use it serves to provide data that is similar to some of the data you already have. A prominent method in machine learning for increasing the amount and variety of the training dataset is data augmentation.
This could enhance the robustness and generalization of machine learning models. A VAE can be used to impute missing data points if your dataset contains missing values or records that are incomplete. You can fill in missing values in a way that is consistent with the learned data distribution by encoding the available data into the latent space and then creating samples from it.
Generating synthetic data that replicates historical or real-world data is crucial for scenario analysis, risk assessment, and even investment strategies in domains like finance, economics, and simulation. For various contexts, VAEs can aid in the development of diverse data sets.
If you want to see more of my work, you can visit my website for the books catalogue by simply following this link:
Creating a Simple Variational Autoencoder
The plan of attack will be to import daily EURUSD data in Python, create the VAE, fit it to the original data, and then use it to generate synthetic data that resembles the original data.
Here’s the simple code to generate data similar to EURUSD using a VAE:
# Importing the required libraries
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
import pandas_datareader as pdr
# Set the start and end dates for the data
start_date = '1990-01-01'
end_date = '2020-01-01'
# Fetch S&P 500 price data
data = np.array((pdr.get_data_fred('DEXUSEU', start = start_date,
end = end_date)).dropna())
# Define the VAE model
latent_dim = 2
encoder = tf.keras.Sequential([
tf.keras.layers.Input(shape=(len(data),)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(latent_dim, activation='relu'),
])
decoder = tf.keras.Sequential([
tf.keras.layers.Input(shape=(latent_dim,)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(len(data), activation='linear'),
])
vae = tf.keras.Model(encoder.inputs, decoder(encoder.outputs))
# Compile the model
vae.compile(optimizer = 'adam', loss = 'mse')
# Normalize the data
normalized_data = (data - np.min(data)) / (np.max(data) - np.min(data))
normalized_data = normalized_data.reshape(1, -1)
# Train the VAE on the normalized data
history = vae.fit(normalized_data, normalized_data, epochs = 1000,
verbose = 0)
# Generate 5 synthetic data points
num_samples = 5
random_latent_vectors = np.random.normal(size=(num_samples, latent_dim))
synthetic_data = decoder.predict(random_latent_vectors)
# Denormalize the synthetic data
synthetic_data = synthetic_data * (np.max(data) - np.min(data)) + \
np.min(data)
# Plot the original and synthetic data
fig, axs = plt.subplots(2, 1)
axs[0].plot(data, label = 'Original Data', color = 'black')
axs[0].legend()
axs[0].grid()
for i in range(num_samples):
plt.plot(synthetic_data[i], label = f'Synthetic Data {i+1}',
linewidth = 1)
plt.xlabel('Time Steps')
plt.ylabel('Value')
plt.legend()
plt.title('Original (black) vs. Synthetic Time Series Data (colored)')
plt.show()
plt.grid()The following Figure shows the values of EURUSD in the first panel with the generated data in the second panel. The generated data can be used to back-test and validate investment strategies on EURUSD. This is an example of data augmentation.
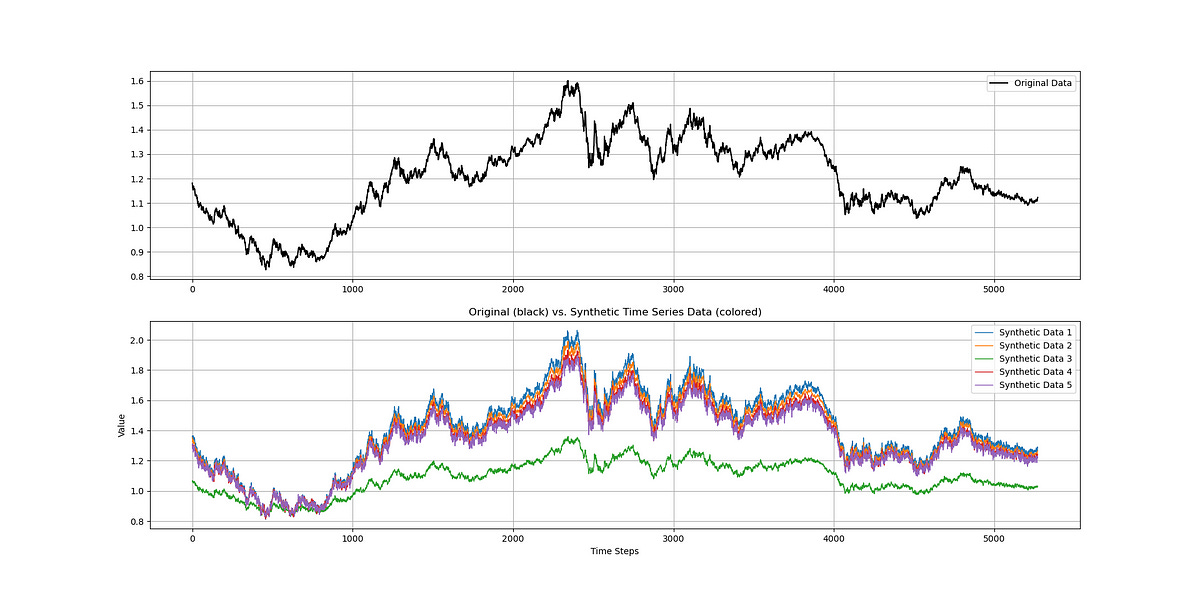
To sum up, a VAE is a probabilistic generative model that can generate new data samples while simultaneously capturing the underlying structure of the data in a lower-dimensional latent space.
You can also check out my other newsletter The Weekly Market Sentiment Report that sends weekly directional views every weekend to highlight the important trading opportunities using a mix between sentiment analysis (COT report, put-call ratio, etc.) and rules-based technical analysis.
If you liked this article, do not hesitate to like and comment, to further the discussion!