
Gamma Exposure Unleashed: A New Frontier in S&P 500 Prediction Using Random Forest
Unraveling the Power of Gamma Exposure and Random Forest


Gamma exposure is a concept commonly associated with options trading, particularly in the field of quantitative finance. Gamma is used to quantify the sensitivity of an option’s price to changes in the underlying asset’s price. It measures the rate of change in an option’s delta (the sensitivity of the option’s value to changes in the underlying asset’s price) as the underlying asset’s price changes.
This article will download historical values relating to gamma exposure and will develop a random forest model that aims to predict the returns of the S&P 500 using the gamma exposure values.
The Gamma Exposure Index
The gamma exposure index (GEX) relates to the sensitivity of option contracts to changes in the underlying price. When imbalances occur, the effects of market makers’ hedges may cause price swings (such as short squeezes). The absolute value of the GEX index is simply the number of shares that will be bought or sold to push the price in the opposite direction of the trend when a 1% absolute move occurs. For example, if the price moves +1% with the GEX at 5.0 million, then, 5.0 million shares will come pouring in to push the market to the downside as a hedge.
The following graph shows the historical values of the GEX.

The GEX is published on a regular basis by squeezemetrics and is free for download.
You can also check out my other newsletter The Weekly Market Sentiment Report that sends tactical directional views every weekend to highlight the important trading opportunities using a mix between sentiment analysis (COT reports, Put-Call ratio, Gamma exposure index, etc.) and technical analysis.

Creating the Algorithm
Our aim is to use the values of the index as inputs to feed a random forest algorithm and fit it to the returns of the S&P 500 index. In layman’s terms, we will be creating a machine learning algorithm that uses the index to predict the upcoming S&P 500’s direction (up or down). Here’s the breakdown of the steps:
Pip install selenium and then download Chrome Webdriver (make sure that it is compatible with your Google Chrome version).
Use the script provided below to download automatically the historical values of the index and the S&P 500. Take the returns and shift the values of the index by a number of lags (in this case, 20).
Clean the data and split it into test and training data.
Fit and predict using the random forest regression algorithm.
Evaluate the results using the hit ratio (accuracy).
Note: The index is stationary. This means that it does not have a trending nature that makes it not suitable for regression.
Use the following code to implement the research:
# Importing Libraries
import pandas as pd
import numpy as np
from selenium import webdriver
from selenium.webdriver.common.by import By
from sklearn.ensemble import RandomForestRegressor
import matplotlib.pyplot as plt
# Calling Chrome
driver = webdriver.Chrome()
# URL of the Website from Where to Download the Data
url = "https://squeezemetrics.com/monitor/dix"
# Opening the website
driver.get(url)
# Getting the button by ID
button = driver.find_element(By.ID, "fileRequest")
# Clicking on the button
button.click()
# Importing the Excel File Using pandas
my_data = pd.read_csv('DIX.csv')
# Transforming the File to an Array
selected_columns = ['price', 'gex']
my_data = my_data[selected_columns]
my_data['gex'] = my_data['gex'].shift(34)
my_data = my_data.dropna()
my_data = np.array(my_data)
plt.plot(my_data[:, 1], label = 'GEX')
plt.legend()
plt.grid()
my_data = pd.DataFrame(my_data)
my_data = my_data.diff()
my_data = my_data.dropna()
my_data = np.array(my_data)
def data_preprocessing(data, train_test_split):
# Split the data into training and testing sets
split_index = int(train_test_split * len(data))
x_train = data[:split_index, 1]
y_train = data[:split_index, 0]
x_test = data[split_index:, 1]
y_test = data[split_index:, 0]
return x_train, y_train, x_test, y_test
x_train, y_train, x_test, y_test = data_preprocessing(my_data, 0.80)
model = RandomForestRegressor(max_depth = 50, random_state = 0)
x_train = np.reshape(x_train, (-1, 1))
x_test = np.reshape(x_test, (-1, 1))
model.fit(x_train, y_train)
y_pred_rf = model.predict(x_test)
same_sign_count_rf = np.sum(np.sign(y_pred_rf) == np.sign(y_test)) / len(y_test) * 100
print('Hit Ratio RF = ', same_sign_count_rf, '%')
plt.plot(y_pred_rf[-100:], label='Predicted Data', linestyle='--', marker = '.', color = 'blue')
plt.plot(y_test[-100:], label='True Data', marker = '.', alpha = 0.7, color = 'red')
plt.legend()
plt.grid()
plt.axhline(y = 0, color = 'black', linestyle = '--')The following Figure compares the predicted versus the real data.
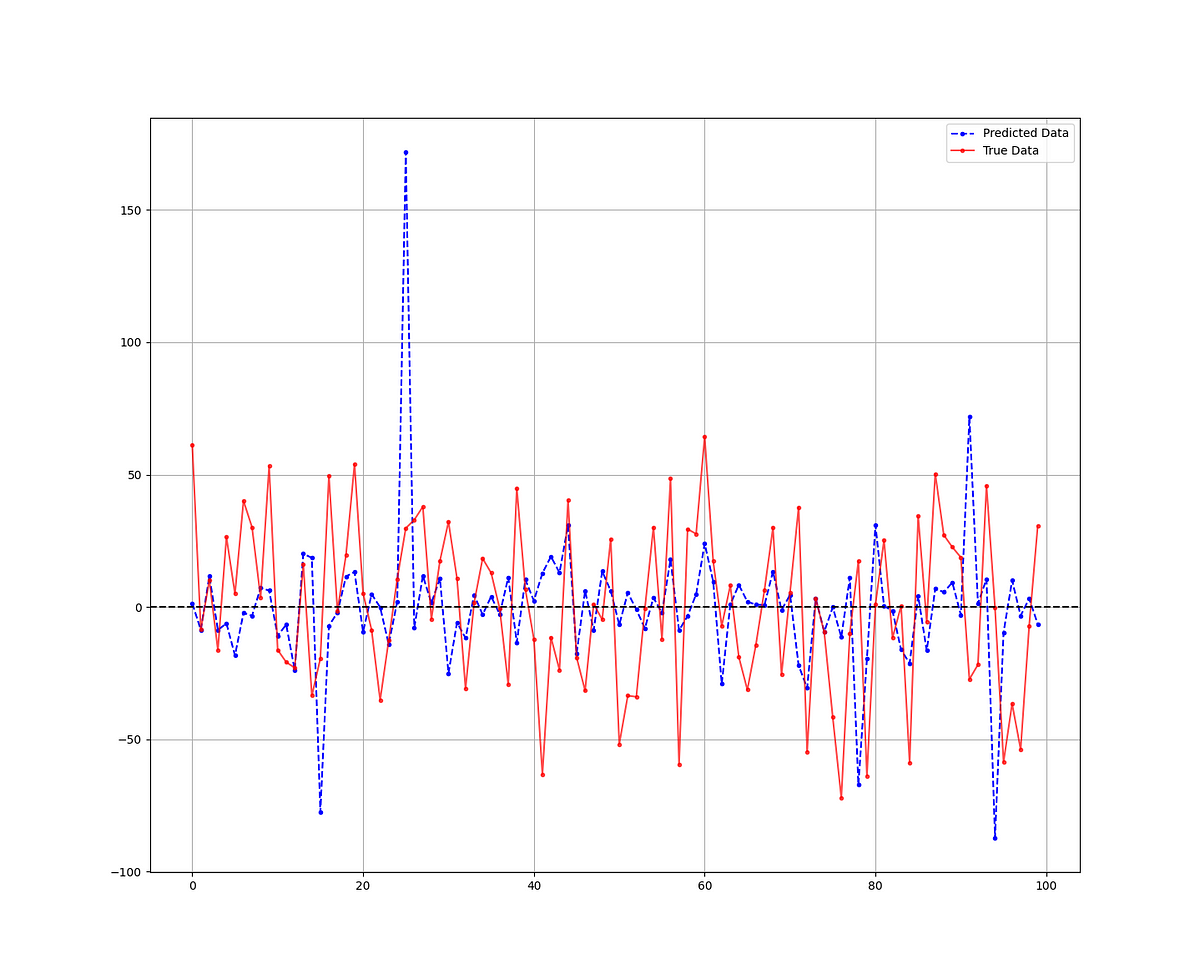
The hit ratio (accuracy) of the algorithm is as follows:
Hit Ratio RF = 57.39549839228296 %It seems that the algorithm has had a 57.34% accuracy in determining whether the S&P 500 index will close in the positive or negative territory, which is not bad.
Other options to explore can include adding more inputs and tuning the hyperparameters of the algorithm.
You can also check out my other newsletter The Weekly Market Analysis Report that sends tactical directional views every weekend to highlight the important trading opportunities using technical analysis that stem from modern indicators. The newsletter is free.
If you liked this article, do not hesitate to like and comment, to further the discussion!