


AI’s Crystal Ball: How Neural Networks Forecast Inflation
The Intersection of AI and Economics for Accurate Forecasting


Traditional methods of inflation forecasting rely heavily on historical data and complex econometric models, which often fail to capture the nuances of rapidly changing economic conditions (with the exception of a few good models). Enter neural networks, particularly LSTM networks, which have revolutionized the way we approach predictive analytics.
This article shows how to create an LSTM model from scratch and use it to predict changes in the monthly inflation measures from the United States.
LSTM Bootcamp
The best way to understand anything is to think about it in simple terms, no math nor complex graphs needed, just pure intuition and logic. Imagine you are reading a book. As you move from chapter to chapter, you remember important details from previous chapters to understand the current one. This ability to recall information from earlier chapters helps you follow the story. Now, think about how a computer might read this book.
Unlike humans, computers typically struggle with remembering past information when processing new information (we at least still have this advantage over computers before they rule us in the future). This is where Long Short-Term Memory (LSTM) networks come in — they help computers remember important details over time, just like you do when reading a book. So, the key word with LSTM networks is memory. But what are LSTMs really?
They are a special type of artificial neural network designed used to process sequences of data. They were created to solve the problem of remembering information over long periods, which standard neural networks can’t handle very well.
Imagine you’re a student trying to learn history. If you could only remember what you learned in the last five minutes, you’d have a tough time connecting events and understanding the broader context. This is similar to how regular neural networks work — they struggle to maintain information over long sequences.
LSTMs are like having a notebook where you can jot down important events as you study history. You can go back to these notes whenever you need to recall previous information, no matter how far back it was. This notebook is your LSTM’s memory.
That’s pretty much what you need to understand on the functionality of LSTMs, let’s leave the boring details for the geeks and proceed with our aim, predicting inflation numbers using a machine learning algorithm based on LSTMs.
Predicting Inflation Using LSTM
First of all, you must understand the type of data you’re analyzing. The U.S. Consumer Price Index (CPI) is a critical economic indicator that measures the average change over time in the prices paid by urban consumers for a basket of goods and services. Essentially, the CPI tracks the cost of living by monitoring price changes for a wide range of items, including food, clothing, shelter, fuels, transportation, medical services, and other goods and services that people buy for day-to-day living.
To make this series stationary, we are interested in predicting the change of the year-over-year CPI measure, that is the monthly rise or fall in inflation.
The plan of attack will be as follows:
Import the required Python libraries and the inflation (CPI) data from the Federal Reserve of Saint-Louis.
Clean the data and split it into a training set and a test set.
Choose an explanatory variable (predictors). In our case, we will simply use lagged changes. This means that we will use past values to predict future values (thus, implying a form of autocorrelation and predictability in the data).
Train the data and predict on the test data.
Evaluate the model using the accuracy (hit ratio) and the root-mean square error (RMSE).
The training data is used to train or fit the model. During this phase, the model learns the underlying patterns and relationships in the data. The algorithm adjusts its parameters based on the training data to minimize the error in its predictions.
The test data is used to evaluate the model’s performance and generalizability on new, unseen data. After the model has been trained, it is tested on this separate dataset to see how well it performs in predicting outcomes.
Use the following code to implement the algorithm:
# Importing the required library
import pandas_datareader as pdr
import matplotlib.pyplot as plt
# Setting the beginning and end of the historical data
start_date = '1950-01-01'
end_date = '2024-01-23'
# Creating a dataframe and downloading the CPI data
data = pdr.DataReader('CPIAUCSL', 'fred', start_date, end_date)
# Checking if there are nan values in the CPI dataframe
count_nan = data['CPIAUCSL'].isnull().sum()
# Printing the result
print('Number of nan values in the CPI dataframe: ' + str(count_nan))
# Transforming the CPI into a year-on-year measure
data = data.pct_change(periods = 12, axis = 0) * 100
# Dropping the nan values from the rows
data = data.dropna()
# Importing libraries
from keras.models import Sequential
from keras.layers import Dense, LSTM
import numpy as np
import pandas_datareader as pdr
from sklearn.metrics import mean_squared_error
def data_preprocessing(data, num_lags, train_test_split):
# Prepare the data for training
x = []
y = []
for i in range(len(data) - num_lags):
x.append(data[i:i + num_lags])
y.append(data[i+ num_lags])
# Convert the data to numpy arrays
x = np.array(x)
y = np.array(y)
# Split the data into training and testing sets
split_index = int(train_test_split * len(x))
x_train = x[:split_index]
y_train = y[:split_index]
x_test = x[split_index:]
y_test = y[split_index:]
return x_train, y_train, x_test, y_test
def plot_train_test_values(window, train_window, y_train, y_test, y_predicted):
prediction_window = window
first = train_window
second = window - first
y_predicted = np.reshape(y_predicted, (-1, 1))
y_test = np.reshape(y_test, (-1, 1))
plotting_time_series = np.zeros((prediction_window, 3))
plotting_time_series[0:first, 0] = y_train[-first:]
plotting_time_series[first:, 1] = y_test[0:second, 0]
plotting_time_series[first:, 2] = y_predicted[0:second, 0]
plotting_time_series[0:first, 1] = plotting_time_series[0:first, 1] / 0
plotting_time_series[0:first, 2] = plotting_time_series[0:first, 2] / 0
plotting_time_series[first:, 0] = plotting_time_series[first:, 0] / 0
plt.plot(plotting_time_series[:, 0], label = 'Training data', color = 'black', linewidth = 2.5)
plt.plot(plotting_time_series[:, 1], label = 'Test data', color = 'black', linestyle = 'dashed', linewidth = 2)
plt.plot(plotting_time_series[:, 2], label = 'Predicted data', color = 'red', linewidth = 1)
plt.axvline(x = first, color = 'black', linestyle = '--', linewidth = 1)
plt.grid()
plt.legend()
def calculate_accuracy(predicted_returns, real_returns):
predicted_returns = np.reshape(predicted_returns, (-1, 1))
real_returns = np.reshape(real_returns, (-1, 1))
hits = sum((np.sign(predicted_returns)) == np.sign(real_returns))
total_samples = len(predicted_returns)
accuracy = hits / total_samples
return accuracy[0] * 100
# Setting the hyperparameters
num_lags = 100
train_test_split = 0.80
num_neurons_in_hidden_layers = 20
num_epochs = 100
batch_size = 32
# Creating the training and test sets
data = np.array(data)
data = np.diff(data[:, 0])
x_train, y_train, x_test, y_test = data_preprocessing(data, num_lags, train_test_split)
# Reshape the data for LSTM input
x_train = x_train.reshape((-1, num_lags, 1))
x_test = x_test.reshape((-1, num_lags, 1))
# Create the LSTM model
model = Sequential()
# First LSTM layer
model.add(LSTM(units = num_neurons_in_hidden_layers, input_shape = (num_lags, 1)))
# Second hidden layer
model.add(Dense(num_neurons_in_hidden_layers, activation = 'relu'))
# Output layer
model.add(Dense(units = 1))
# Compile the model
model.compile(loss = 'mean_squared_error', optimizer = 'adam')
# Train the model
model.fit(x_train, y_train, epochs = num_epochs , batch_size = batch_size)
# Predicting in-sample
y_predicted_train = np.reshape(model.predict(x_train), (-1, 1))
# Predicting out-of-sample
y_predicted = np.reshape(model.predict(x_test), (-1, 1))
# plotting
y_test = np.reshape(y_test, (-1))
y_train = np.reshape(y_train, (-1))
plot_train_test_values(100, 50, y_train, y_test, y_predicted)The code comes from my newest book on Deep Learning:
Deep Learning for Finance: Creating Machine & Deep Learning Models for Trading in Python
Deep Learning for Finance: Creating Machine & Deep Learning Models for Trading in Python [Kaabar, Sofien] on…amzn.to
The plotting function should give you the following chart:
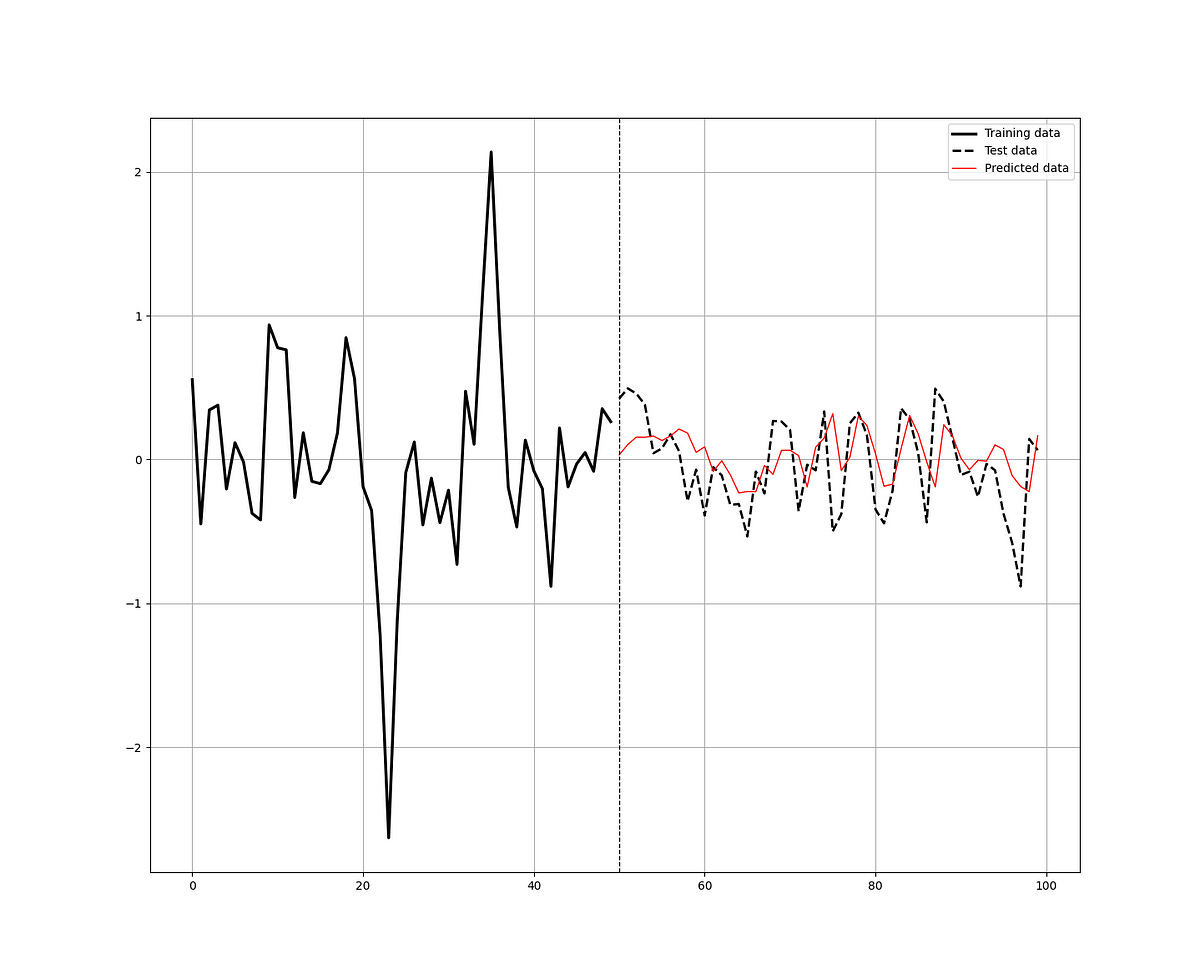
Let’s evaluate the algorithm using the functions we have previously defined:
# Performance evaluation
print('---')
print('Accuracy Train = ', round(calculate_accuracy(y_predicted_train, y_train), 2), '%')
print('Accuracy Test = ', round(calculate_accuracy(y_predicted, y_test), 2), '%')
print('RMSE Train = ', round(np.sqrt(mean_squared_error(y_predicted_train, y_train)), 10))
print('RMSE Test = ', round(np.sqrt(mean_squared_error(y_predicted, y_test)), 10))
print('Correlation In-Sample Predicted/Train = ', round(np.corrcoef(np.reshape(y_predicted_train, (-1)), y_train)[0][1], 3))
print('Correlation Out-of-Sample Predicted/Test = ', round(np.corrcoef(np.reshape(y_predicted, (-1)), np.reshape(y_test, (-1)))[0][1], 3))
print('---')The output of the previous code is as follows:
---
Accuracy Train = 62.58 %
Accuracy Test = 70.51 %
RMSE Train = 0.3287812546
RMSE Test = 0.3275757807
Correlation In-Sample Predicted/Train = 0.522
Correlation Out-of-Sample Predicted/Test = 0.509
---When developing and deploying predictive models, especially in critical fields like finance, it is crucial to conduct extensive research before relying on any model. Do your homework!
You can also check out my other newsletter The Weekly Market Sentiment Report that sends weekly directional views every weekend to highlight the important trading opportunities using a mix between sentiment analysis (COT report, put-call ratio, etc.) and rules-based technical analysis.
If you liked this article, do not hesitate to like and comment, to further the discussion!