
Advanced Techniques for Evaluating Machine Learning Models in Time Series Analysis
A Guide to Unconventional Performance Metrics


Performance evaluation metrics for machine learning algorithms in the context of time series data often focus on aspects such as forecasting accuracy, model interpretability, and computational efficiency.
While there are many standard metrics like mean absolute error (MAE), mean squared error (MSE), and root mean squared error (RMSE), you can explore more exotic or specialized metrics to gain deeper insights into your model’s performance.
Machine Learning and Performance Evaluation
Performance evaluation in time series forecasting is the process of assessing how well a machine learning model predicts future values in a time-ordered sequence. It is crucial for understanding the quality of forecasts, model selection, and refining predictive algorithms.
This article will generate a synthetic time series, fit a linear regression model to understand it, predict the future values, and finally present a few exotic model evaluation metrics.
The generated time series will be a simple and clean sine wave as illustrated in the following graph.
The Python framework of the analysis is as follows:
Generate a simple sine wave time series.
Split the time series into a training and test data.
Fit the model and predict on the test set.
The following sections will show new evaluation metrics.
Use the code to develop the algorithm:
import numpy as np
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
import pandas as pd
def data_preprocessing(data, num_lags, train_test_split):
# Prepare the data for training
x = []
y = []
for i in range(len(data) - num_lags):
x.append(data[i:i + num_lags])
y.append(data[i+ num_lags])
# Convert the data to numpy arrays
x = np.array(x)
y = np.array(y)
# Split the data into training and testing sets
split_index = int(train_test_split * len(x))
x_train = x[:split_index]
y_train = y[:split_index]
x_test = x[split_index:]
y_test = y[split_index:]
return x_train, y_train, x_test, y_test
# Parameters
amplitude = 4.0
frequency = 3.0
duration = 15.25
sampling_frequency = 100
# Generate time values
t = np.linspace(0, duration, int(sampling_frequency * duration), endpoint=False)
# Generate the sine wave
data = amplitude * np.sin(2 * np.pi * frequency * t)
'''
plt.plot(data[-250:], label = 'Sine Wave', linewidth = 1)
plt.grid()
plt.legend()
plt.axhline(y = 0, color = 'black', linewidth = 1)
'''
x_train, y_train, x_test, y_test = data_preprocessing(data, 100, 0.70)
# Create the model
model = LinearRegression()
# Fit the model to the data
model.fit(x_train, y_train)
# Predict on the same data used for training
y_pred = model.predict(x_test)
# Plotting
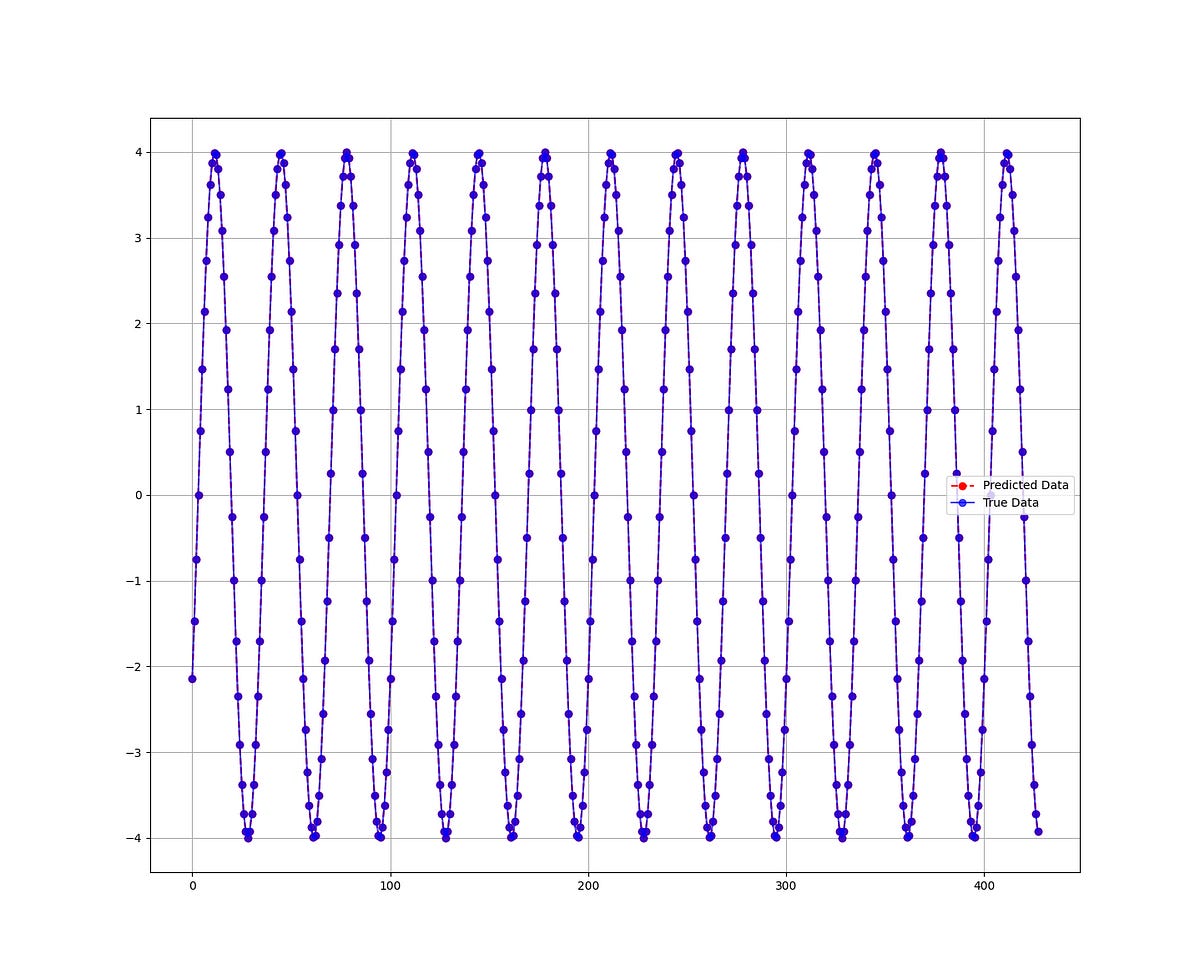
plt.plot(y_pred, label='Predicted Data', linestyle='--', marker = 'o', color = 'red')
plt.plot(y_test, label='True Data', marker = 'o', alpha = 0.7, color = 'blue')
plt.legend()
plt.grid()You can also check out my other newsletter The Weekly Market Sentiment Report that sends tactical directional views every weekend to highlight the important trading opportunities using a mix between sentiment analysis (COT reports, Put-Call ratio, Gamma exposure index, etc.) and technical analysis.
The following shows a comparison between predicted and real data.
Symmetric Mean Absolute Percentage Error
The symmetric mean absolute percentage error (sMAPE) is a metric used to evaluate the accuracy of forecasts, especially in time series forecasting. It is a variant of the mean absolute percentage error (MAPE) but addresses the issue of asymmetric errors in MAPE.
sMAPE calculates the percentage difference between predicted and actual values while symmetrically handling both overestimation and underestimation. The formula for sMAPE is as follows:

With F as the forecast and A as the actual (real) value. The sMAPE formula calculates the absolute percentage difference between the actual and predicted values for each time point, scales it by 2, and divides by the sum of the absolute values of the actual and predicted values. This symmetric scaling allows for both underestimation and overestimation to be treated fairly.
sMAPE is calculated for each time point, and then you can calculate the average sMAPE across all time points to get an overall measure of forecast accuracy. Interpreting specific sMAPE values may depend on the context and the nature of the data. In general, you can interpret it as follows:
sMAPE < 10%: This suggests a very accurate forecast, indicating that the model’s predictions are extremely close to the actual values.
10% < sMAPE < 20%: This range is often considered acceptable for many forecasting applications. It implies a reasonably good level of accuracy.
sMAPE > 20%: This may indicate relatively poor forecast accuracy, and the model’s predictions are not very close to the actual values.
Use the following code for the metric:
def calculate_smape(actual, predicted):
n = len(actual)
smape_sum = 0
for i in range(n):
numerator = 2 * np.abs(actual[i] - predicted[i])
denominator = np.abs(actual[i]) + np.abs(predicted[i])
smape_sum += numerator / denominator
smape = (1 / n) * smape_sum * 100
return smape
smape_value = calculate_smape(y_test, y_pred)
print(f"sMAPE: {smape_value:.2f}%")The result should be as follows:
sMAPE: 1.47%As expected, a simple sine wave can easily be predicted with low errors using a linear regression algorithm. With a value of 1.47%, the sMAPE indicates that the model’s predictions are extremely close to the actual values.
You can also check out my other newsletter The Weekly Market Analysis Report that sends tactical directional views every weekend to highlight the important trading opportunities using technical analysis that stem from modern indicators. The newsletter is free.
If you liked this article, do not hesitate to like and comment, to further the discussion!
The Windowed Mean Absolute Error
MAE stands for mean absolute error. It is a common metric used to measure the accuracy of a predictive model, typically in the context of regression analysis or time series forecasting. MAE quantifies the average magnitude of errors between predicted values and actual values. It is a straightforward and interpretable metric.
The formula for calculating MAE is as follows:
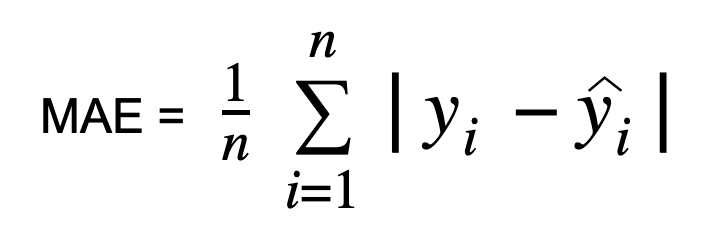
In words, MAE computes the absolute difference between each predicted value and its corresponding actual value, sums up these absolute differences across all data points, and then takes the average by dividing by the total number of data points (n).
A lower MAE indicates better model accuracy, as it means that, on average, the model’s predictions are closer to the actual values. The windowed MAE simply calculates the MAE on a moving window, thus reflecting a dynamic version of it.
Use the following code for the metric:
def windowed_mae(actual, predicted, window_size):
n = len(actual)
mae_values = []
for i in range(n - window_size + 1):
window_actual = actual[i : i + window_size]
window_predicted = predicted[i : i + window_size]
mae = np.mean(np.abs(window_actual - window_predicted))
mae_values.append(mae)
return np.array(mae_values)
mae_values = windowed_mae(y_test, y_pred, 100)
plt.plot(mae_values, label = 'Windowed MAE (Lookback = 100')
plt.grid()
plt.legend()The following chart shows the windowed MAE.

Rising values indicate higher recent errors.
Rolling Winning Streak
A rolling winning streak may be interesting to show you the number of consecutive periods that the algorithm is able to correctly predict. Here’s how it works:
An array is created to hold the values of the winning streak.
A value of 1 is added to the previous value in the array if the predicted value matches the sign of the actual value.
A value of 0 is inputted if the sign does not match. The counter therefore resumes from 0 and starts counting again.
Use the following code for the metric:
def winning_streak(actual, predicted):
counts = []
count = 0
for i in range(len(actual)):
if (actual[i] > 0 and predicted[i] > 0) or (actual[i] < 0 and predicted[i] < 0):
count += 1
counts.append(count)
else:
count = 0
counts.append(count)
counts = np.array(counts)
return counts
streak = winning_streak(y_test, y_pred)
plt.plot(streak, label = 'Winning Streak')
plt.legend()
plt.grid()The following chart shows the winning streak on the test set.

Frequent returns to zero is a sign that the model may be more random in nature. However, extended periods above zero indicate that the model may have periods where it forecasts well the data.
A good idea would be to calculate the mean of the streak metric:
np.mean(streak)The result is as follows:
125.71125 suggests that on average, the model predicts that number of correct consecutive values before making a mistake.
Model Bias
Model bias may be a little less exotic than the previous three metrics. It is simply the ratio of the up predictions relative to the down predictions. Naturally, it is an equilibrium metric as opposed to an accuray metric, as it measures the extent by which the model is biased to the upside or the downside.
The optimal value is 1.00, which simply means that the model has a 50% chance of predicting a move up or a move down.
Use the following code for the metric:
def model_bias(predicted_returns):
up_predictions = np.sum(predicted_returns > 0)
down_predictions = np.sum(predicted_returns < 0)
return up_predictions / down_predictions
model_bias(y_pred)The result of the code is as follows:
1.0188679245283019With a symmetrical oscillating sine wave, it is expected to have a value extremely close 1.00.