
A-Z Machine Learning: Linear Regression in Time Series Analysis
A Deep Understanding and Visualization of Linear Regression


Linear regression is sometimes looked down upon due to its simplicity and its linear-dependent outputs. However, a lot of complex forecasting tasks can be solved using linear regression. I was once told by a very successful hedge fund manager that one of their sophisticated trading models relied on a simple linear regression model.
This article shows you everything you need to know about linear regression, and presents a full example of applying it on time series in order to predict the future values.
Intuition of Linear Regression
Linear regression is a statistical method used for modeling the relationship between a dependent variable (the output or target variable) and one or more independent variables (features or predictors). The goal is to find the best-fit linear relationship that explains the variation in the dependent variable based on the independent variables.
Linear regression assumes that the relationship between the independent and dependent variables is linear. This means that changes in the dependent variable are proportional to changes in the independent variable(s). The best-fit line is determined by minimizing the sum of squared differences between the observed values of the dependent variable and the values predicted by the linear model. This process is known as the method of least squares.
The simple linear regression formula is typically represented as:

Here’s what each part means:
Y is the dependent variable, which is the variable you are trying to predict.
X is the independent variable, the variable you are using to make predictions about the dependent variable. This can either be an exogenous variable or a lagged endogenous variable (such as a lagged value of Y).
b0 is the y-intercept, which represents the value of Y when X is 0. In other words, it’s the predicted value of Y when X is not influencing it.
b1 is the slope of the regression line, representing the change in Y for a one-unit change in X. It shows the strength and direction of the relationship between X and Y.
ε is the error term, which accounts for the variability in Y that the model cannot explain. It’s the difference between the observed Y and the predicted Y values.
So, when you plug in values for X into the formula, you get a predicted Y based on the slope and y-intercept. The error term accounts for the difference between this predicted Y and the actual observed Y.
In simpler terms, linear regression finds the line that best represents the relationship between the input variables and the output variable. The coefficients determine the slope and intercept of this line. The goal is to minimize the difference between the observed and predicted values, making the line the best fit for the given data.
Linear regression relies on several assumptions to provide accurate and reliable results. Here are the key assumptions of linear regression, explained in simpler terms:
Linearity: The relationship between the independent and dependent variables is linear. This means that changes in the dependent variable are proportional to changes in the independent variable(s). In other words, this means that the best-fit line is a straight line.
Independence of errors: The errors (residuals) between observed and predicted values are independent. The error in predicting one data point should not influence the error in predicting another. This implies that there is no pattern in the residuals, and no correlation between errors.
Homoscedasticity: The variance of the errors is constant across all levels of the independent variable(s).
Normality of errors: The errors are normally distributed. This assumption is more crucial for smaller sample sizes. Therefore, the distribution of residuals follows a bell-shaped curve.
No perfect multicollinearity: There is no perfect linear relationship between independent variables. In other words, one independent variable should not be a perfect predictor of another. Each independent variable provides unique information to the model.
You can also check out my other newsletter The Weekly Market Sentiment Report that sends tactical directional views every weekend to highlight the important trading opportunities using a mix between sentiment analysis (COT reports, Put-Call ratio, Gamma exposure index, etc.) and technical analysis.
Evaluating a Linear Regression Model
There are many ways to evaluate the linear regression model. If you are interested in a binary directional model (such as positive change and negative change), then you can add accuracy as a performance criteria. We will see how the binary model works.
Here are some other ways you can evaluate the model:
Mean absolute error (MAE): Average of the absolute differences between predicted and observed values. Lower values are better.

Mean squared error (MSE): Average of the squared differences between predicted and observed values. Commonly used but sensitive to outliers.

Root mean squared error (RMSE): Square root of MSE. Provides a measure in the same units as the dependent variable. Like MSE, sensitive to outliers.
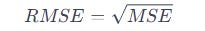
Mean absolute percentage error (MAPE): Average of the percentage differences between predicted and observed values. Useful when dealing with relative errors.

There is another way called R² which requires a section on its own. Let’s check it out.
The Significance of R² in Linear Regression
the coefficient of determination (R²) is a statistical measure that tells you how well the independent variable (or variables) in your model explains the variation in the dependent variable. In simpler terms, it indicates the proportion of the variance in the dependent variable that can be predicted or explained by the independent variable(s) in your model.
The R² value ranges from 0 to 1, where 0 means that the model doesn’t explain any variability in the dependent variable, and 1 means that the model perfectly explains all the variability. So, a higher R² indicates a better fit of your model to the data.
However, it’s crucial to understand that a high R² doesn’t necessarily mean that your model is perfect or that it has a causal relationship. It just quantifies how well the model fits the observed data. It’s always essential to consider other factors and context when interpreting R² in the real world.
In finance, R² is often used in regression analysis to assess the goodness of fit of a model, helping you understand how much of the variability in an asset’s returns can be explained by factors like market movements or other variables included in the model.

Fun fact: R² is simply a squared correlation coefficient.
The calculation of R² involves comparing the variability explained by your model with the total variability in the dependent variable.
The adjusted R² is a modification of the regular R² value in linear regression analysis. While R² represents the proportion of the variance in the dependent variable explained by the independent variable(s), the adjusted R² adjusts this value based on the number of predictors in the model.
The adjusted R² takes into account the number of predictors in the model. It penalizes the inclusion of irrelevant predictors that do not significantly contribute to explaining the variance in the dependent variable.

In layman’s terms, the adjusted R-squared provides a more realistic assessment of the model’s goodness of fit by considering the trade-off between model complexity and explanatory power. It helps guard against overfitting by reducing the R-squared value if additional predictors do not substantially improve the model.
A higher adjusted R-squared indicates that a larger proportion of the variance is explained by the relevant predictors, considering the number of predictors in the model. It is a useful metric for comparing models with different numbers of predictors.
A Practical Python Example
Linear regression is like drawing a straight line through a scatterplot of data points. Imagine you have data on house sizes and their prices. You collect this information and use it to find the best-fitting line that goes through most of the points. This line represents the general trend: as houses get bigger, their prices tend to go up.
Now, let’s take a time series example and try to forecast its future values. This time series will be a famous economic indicator called the non-farm payrolls.
Non-farm payrolls (NFP) is a critical and widely watched economic indicator in the United States, serving as a key barometer for the health of the country’s labor market. This monthly employment report provides a comprehensive snapshot of the employment situation in the United States, excluding jobs in the agricultural sector, private households, and nonprofit organizations.
The NFP report reveals the net change in the total number of paid employees in the United States, excluding these specific sectors, during the previous month. It is particularly significant because it offers insights into the overall strength and direction of the U.S. economy. By analyzing the data, economists, policymakers, investors, and businesses can gauge the health of the labor market, track employment trends, and make informed decisions regarding economic policies, investments, and hiring practices.
Moreover, the NFP report’s influence extends beyond the financial markets, as it often impacts currency exchange rates, interest rate decisions, and other financial instruments. Economists try to forecast the upcoming number every month. Let’s try to apply our own model and see what it tells us.
The plan of attack is as follows:
Download the NFP data from this GitHub repository and upload it to Python.
Take the differences of the NFP data. It is already stationary, but we do this to measure the directional accuracy.
Split the data into a training set and a test set.
Fit the model using the last five NFP changes (thus, binary) as features. Then, predict on never-seen-before data in the test set.
Evaluate and compare the predicted versus real data.
Use the following code to implement the process (make sure to download the NFP data from the repository):
import numpy as np
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.metrics import r2_score
def data_preprocessing(data, num_lags, train_test_split):
# Prepare the data for training
x = []
y = []
for i in range(len(data) - num_lags):
x.append(data[i:i + num_lags])
y.append(data[i+ num_lags])
# Convert the data to numpy arrays
x = np.array(x)
y = np.array(y)
# Split the data into training and testing sets
split_index = int(train_test_split * len(x))
x_train = x[:split_index]
y_train = y[:split_index]
x_test = x[split_index:]
y_test = y[split_index:]
return x_train, y_train, x_test, y_test
# Set the time index if it's not already set
data = pd.read_excel('NFP.xlsx').values
data = np.reshape(data, (-1))
data = np.diff(data)
# Taking the first 80% of the data as training (then, testing on the remaining
# 20%. Also, taking the previous 5 changes in NFP as predictors for the next
# value.
x_train, y_train, x_test, y_test = data_preprocessing(data, 5, 0.80)
# Create a CatBoostRegressor model
model = LinearRegression()
# Fit the model to the data
model.fit(x_train, y_train)
# Predict on the same data used for training
y_pred = model.predict(x_test)
# Plot the original sine wave and the predicted values
plt.plot(y_pred[-50:], label='Predicted Data', linestyle='--', marker = '.')
plt.plot(y_test[-50:], label='True Data', marker = '.')
plt.legend()
plt.grid()
plt.axhline(y = 0, color = 'black', linestyle = '--')
import math
from sklearn.metrics import mean_squared_error
rmse_test = math.sqrt(mean_squared_error(y_pred, y_test))
print(f"RMSE of Test: {rmse_test}")
same_sign_count = np.sum(np.sign(y_pred) == np.sign(y_test)) / len(y_test) * 100
print('Directional Accuracy = ', same_sign_count, '%')
r_squared_sklearn = r2_score(y_test, y_pred)
print("R-squared:", r_squared_sklearn)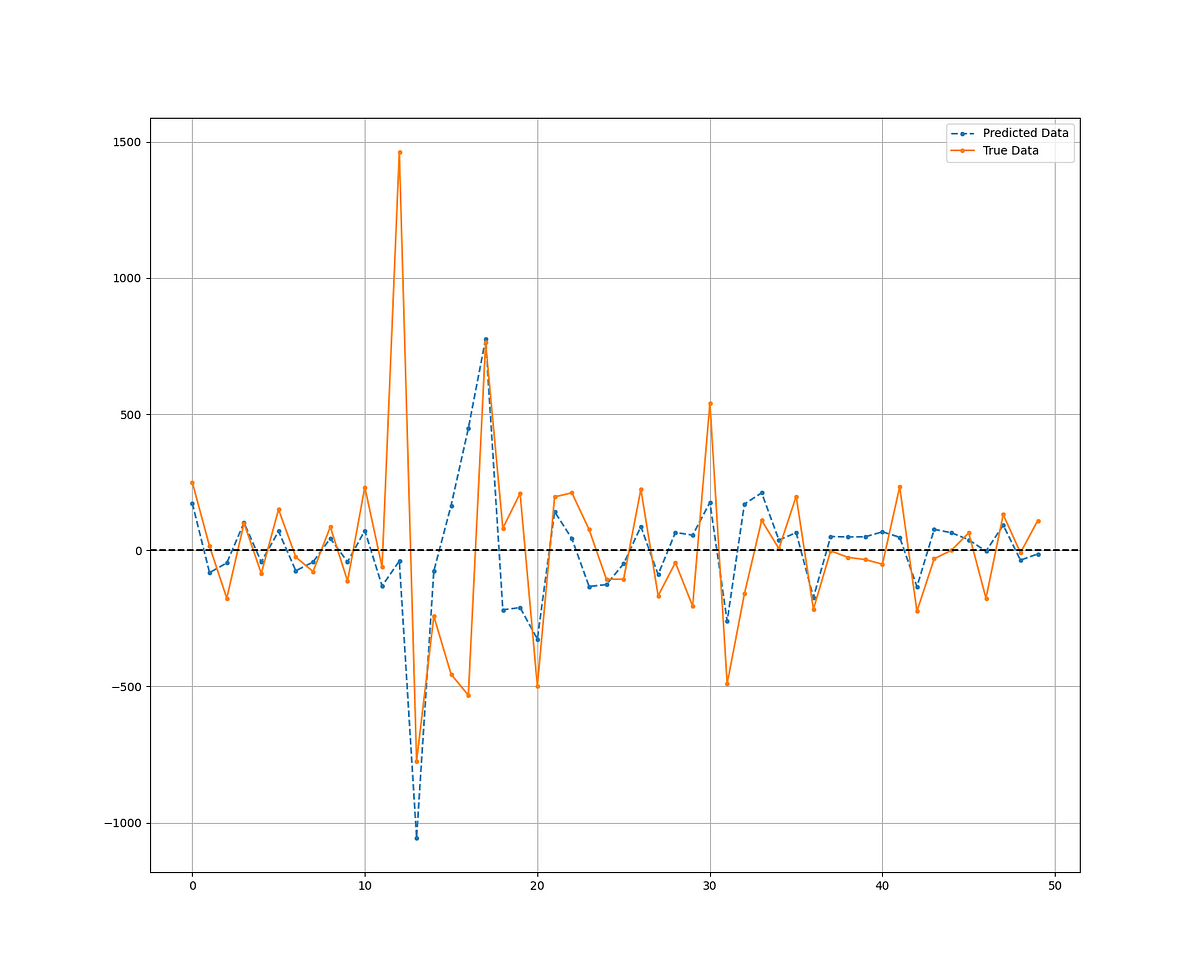
The output of the code is as follows:
RMSE of Test: 188.81
Directional Accuracy = 69.65 %
R-squared (using scikit-learn): 0.12It seems that with a directional accuracy of 69.65%, the model is able to predict whether there will be a positive or a negative change from the last change. The RMSE shows that the forecasts have an error term of around 188. This leaves much room for improvement.
Improvement can be in the sense of adding more features, changing the number of lagged inputs, and adding any other conditions.
In the context of a linear regression model trained using Python’s scikit-learn library, you can obtain the coefficients using the coef_ and intercept_ attributes of the trained model:
print(model.intercept_)
print(model.coef_)You should get the following:
0.04687795592251226
[ 0.04299374 -0.1095549 -0.23853919 -0.41861036 -0.71249265]Therefore, the linear regression formula will have an intercept of 0.046 with coefficients to every lagged variable as follows: {0.04299374 -0.1095549 -0.23853919 -0.41861036 -0.71249265}.
You can also check out my other newsletter The Weekly Market Analysis Report that sends tactical directional views every weekend to highlight the important trading opportunities using technical analysis that stem from modern indicators. The newsletter is free.
If you liked this article, do not hesitate to like and comment, to further the discussion!