
A Simplified Guide to Time Series Analysis Using Neural Networks
Creating an MLP Algorithm to Analyze Time Series


In this beginner’s guide, we’ll explore the advantages and limitations of mutliple-layer perceptrons (MLPs), learn how to prepare financial data, and discover the steps to build, train, and evaluate your own forecasting model.
Deep Learning and MLPs in Layman’s Terms
Deep learning is a subset of machine learning, a type of artificial intelligence, that focuses on training neural networks with multiple layers to automatically learn and extract patterns and representations from data. These deep neural networks can understand and make decisions from complex and large datasets, and they are particularly effective for tasks like image recognition, natural language processing, and time series forecasting. Deep learning has revolutionized AI by enabling the development of highly accurate models for a wide range of applications.
Neural networks are computational models inspired by the human brain’s structure and function. They consist of interconnected nodes, called neurons, organized into layers. These networks are designed to process and learn from data. Each connection between neurons has a weight, and neural networks adjust these weights during training to make predictions or decisions based on input data. They are a fundamental component of machine learning and deep learning, enabling tasks such as image recognition, language processing, and pattern recognition.
At its core, an MLP is a type of artificial neural network characterized by its multiple layers. Don’t worry if that sounds a bit technical — we’ll unravel the layers one by one. Picture it like a stack of interconnected nodes, each layer transforming input into meaningful output.
An MLP typically consists of three main layers:
Input layer: This is where the network receives information. Each node in this layer represents a feature of your input data.
Hidden layers: The magic happens here. These layers process the input data through a series of weights and activation functions, extracting patterns and relationships.
Output layer: The final layer produces the network’s prediction or classification. It’s like the ultimate decision-maker.
MLPs are not born geniuses; they learn through a process called training. During training, the network adjusts its weights based on the error in its predictions, getting better at making accurate guesses over time. It’s like teaching a dog new tricks, but with a lot more math. In each node, an activation function decides whether the node “fires” or not, influencing the information passed to the next layer. Think of it as the spice in your neural network recipe — it adds flavor and complexity.
Ever wondered how MLPs refine their predictions? Enter backpropagation. This nifty technique adjusts the weights backward, minimizing the difference between the predicted and actual outcomes. It’s like fine-tuning your guitar strings for the perfect melody.
MLPs are keen learners, but sometimes they can get too good at memorizing the training data. Overfitting is their Achilles’ heel. Regularization techniques come to the rescue, preventing them from becoming too rigid and inflexible.
The following illustration shows how an MLP functions.

Creating the Algorithm
The aim of the experiment is to use the MLPs as a regression over lagged values of the core US CPI data (inflation) in order to forecast the next direction (more inflation or less inflation).
The framework of the algorithm is as follows:
Import the core US CPI data using Python.
Difference the data twice. The first difference is to make it stationary and the second one to measure the up or down effect in inflation (due to inflationary environment, if you try to forecast the change in CPI, you will end up with a 100% accuracy as it is almost always above zero).
Split the data into training and test. Reshape it, and fit the data to the MLP architecture.
Predict and evaluate the results using the accuracy metric.
Use the following code to create the algorithm:
# Importing libraries
from keras.models import Sequential
from keras.layers import Dense
import numpy as np
import matplotlib.pyplot as plt
import pandas_datareader as pdr
# Set the start and end dates for the data
start_date = '1980-01-01'
end_date = '2023-12-01'
# Fetch S&P 500 price data
data = np.array((pdr.get_data_fred('CPILFESL', start = start_date, end = end_date)).dropna())
# Difference the data and make it stationary
data = np.diff(data[:, 0])
data = np.diff(data[:])
# Setting the hyperparameters
num_lags = 100
train_test_split = 0.90
num_neurons_in_hidden_layers = 500
num_epochs = 100
batch_size = 16
def data_preprocessing(data, num_lags, train_test_split):
# Prepare the data for training
x = []
y = []
for i in range(len(data) - num_lags):
x.append(data[i:i + num_lags])
y.append(data[i+ num_lags])
# Convert the data to numpy arrays
x = np.array(x)
y = np.array(y)
# Split the data into training and testing sets
split_index = int(train_test_split * len(x))
x_train = x[:split_index]
y_train = y[:split_index]
x_test = x[split_index:]
y_test = y[split_index:]
return x_train, y_train, x_test, y_test
# Creating the training and test sets
x_train, y_train, x_test, y_test = data_preprocessing(data, num_lags, train_test_split)
# Create the model
model = Sequential()
# First layer
model.add(Dense(num_neurons_in_hidden_layers, input_dim = num_lags,
activation = 'relu'))
# More hidden layers
model.add(Dense(num_neurons_in_hidden_layers, activation = 'relu'))
model.add(Dense(num_neurons_in_hidden_layers, activation = 'relu'))
model.add(Dense(num_neurons_in_hidden_layers, activation = 'relu'))
model.add(Dense(num_neurons_in_hidden_layers, activation = 'relu'))
model.add(Dense(num_neurons_in_hidden_layers, activation = 'relu'))
model.add(Dense(num_neurons_in_hidden_layers, activation = 'relu'))
# Output layer
model.add(Dense(units = 1))
# Compile the model
model.compile(loss = 'mean_squared_error', optimizer = 'adam')
# Train the model
model.fit(x_train, y_train, epochs = num_epochs , batch_size = batch_size)
# Predicting out-of-sample
y_pred = np.reshape(model.predict(x_test), (-1))
# Plotting
plt.plot(y_pred[-100:], label='Predicted Data', linestyle='--', marker = '.', color = 'red')
plt.plot(y_test[-100:], label='True Data', marker = '.', alpha = 0.7, color = 'blue')
plt.legend()
plt.grid()
plt.axhline(y = 0, color = 'black', linestyle = '--')
same_sign_count = np.sum(np.sign(y_pred) == np.sign(y_test)) / len(y_test) * 100
print('Hit Ratio = ', same_sign_count, '%')The following figure shows the difference between real and predicted values:
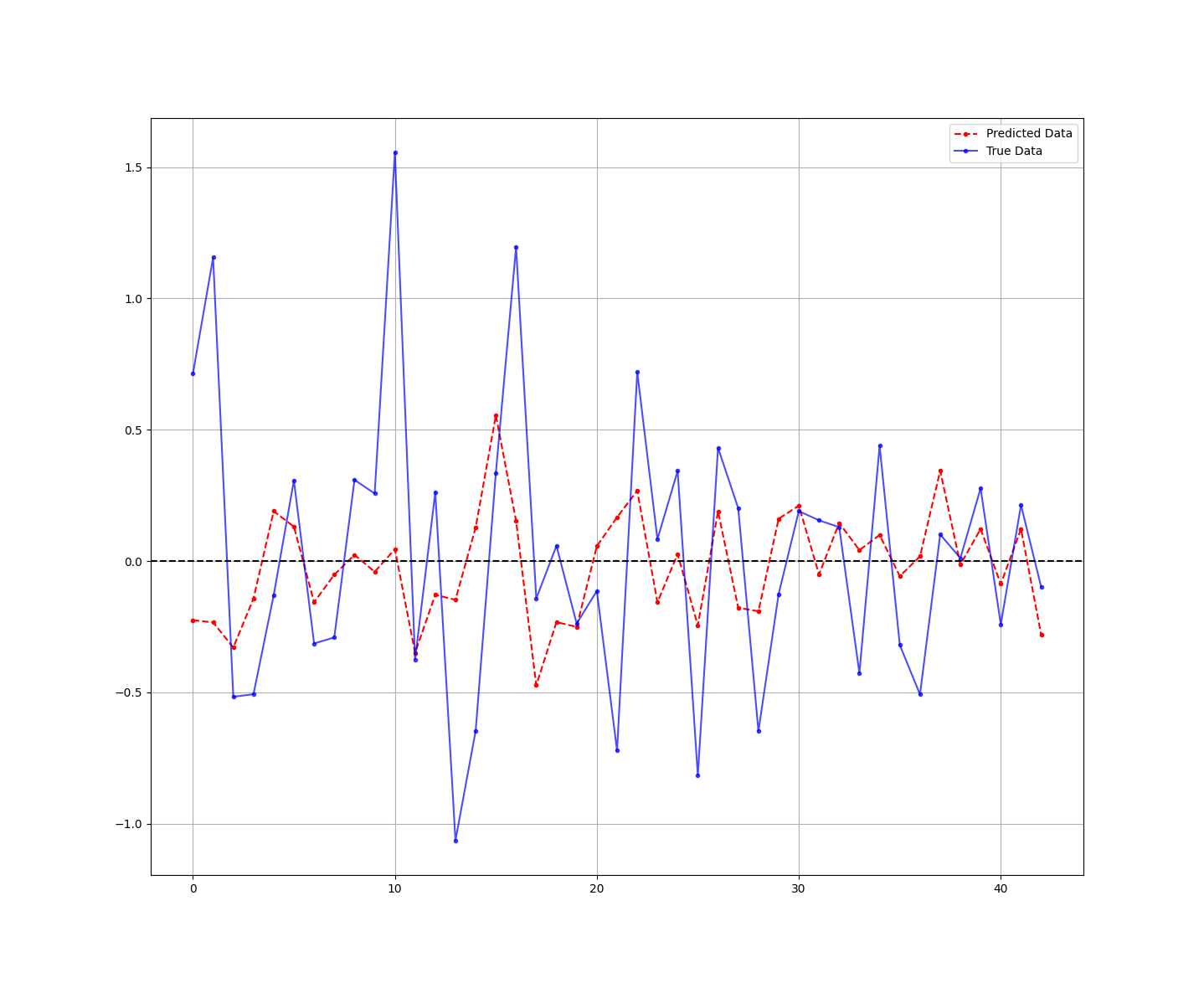
The results are as follows:
Hit Ratio = 62.80 %It is always important to optimize the hyperparameters that were in the code. Hyperparameters are tuned to better fit the data. Here’s a non-exhaustive list of possible hyperparameters:
Number of lags: These are the number of values the algorithm will look at to understand the distribution of the data. If you set it to 5, then the regression task will look at the last 5 observations to try to understand the current one.
The train-test split: This is the frontier between the training data that will come up with the nature of the relationship between the variables and the test data that will validate the relationship through what is known as a back-test. By default, it should be upwards of 0.70 (70% of the data is reserved for training).
The number of neurons in the hidden layers: This is the number of neurons in each hidden layer of the architecture. More neurons means more complexity and ability to detect patterns up to a certain plateau.
The number of hidden layers: More hidden layers are synonymous to a deeper network.
The number of epochs: Epochs are the number of times the model goes through the training data. More epochs will give the algorithm time to understand and learn from its errors.
You can also check out my other newsletter The Weekly Market Sentiment Report that sends weekly directional views every weekend to highlight the important trading opportunities using a mix between sentiment analysis (COT report, put-call ratio, etc.) and rules-based technical analysis.
If you liked this article, do not hesitate to like and comment, to further the discussion!